Ruby on Rails チュートリアル








Ruby on Rails チュートリアル
プロダクト開発の0→1を学ぼう
第2版 目次
- 第1章ゼロからデプロイまで
- 第2章デモアプリケーション
- 第3章ほぼ静的なページの作成
- 第4章Rails風味のRuby
- 第5章レイアウトを作成する
- 第6章ユーザーのモデルを作成する
- 第7章ユーザー登録
- 第8章サインイン、サインアウト
- 第9章ユーザーの更新・表示・削除
- 第10章ユーザーのマイクロポスト
- 第11章ユーザーをフォローする
第6章ユーザーのモデルを作成する
第5章では、新しいユーザーを作成するためのスタブページを作ったところで終わりました (5.4)。これから4つの章を通して、ユーザー登録ページを作っていくことにしましょう。最初の一番重要なステップは、サイトのユーザー用のデータモデルの作成と、データを保存する手段の確保です。第7章では、ユーザーがサイトにユーザー登録できるようにし、ユーザープロファイルのためのページを作成します。ユーザー登録ができるようになると、次にサインイン、サインアウトもできるようにします (第8章)。そして第9章 (9.2.1) では、不正なアクセスから守る方法を学びます。まとめると、第6章から第9章を通して、Railsのログインと認証のシステムをひととおり開発します。ご存知の方もいると思いますが、Railsでは既にさまざまな認証方法が利用可能です。コラム 6.1では、最初に少なくとも一度は自分で認証システムを作ってみることをお勧めする理由について説明しています。
この章は長いうえに、学ぶことがたくさんあります。特に、これまでデータモデリングをしたことがない人にとっては、もしかすると、これまでとは違った難しさを感じるかもしれません。しかし、この章が終わるまでには、ユーザー情報の検証、保存、取得ができる極めて強力なシステムを作成します。
Gitでバージョン管理を行なっているのであれば、このタイミングでユーザーをモデリングするためのトピックブランチを作成しておいてください。
$ git checkout master
$ git checkout -b modeling-users
(最初の行はmasterブランチから作業を始めることを確認するためのものです。そして、modeling-usersトピックブランチはmasterブランチを基に作成します。もしすでにmasterブランチにいる場合は、このコマンドを実行する必要はありません)。
6.1 Userモデル
ここから3つの章にわたる最終目標はユーザー登録ページ (図6.1のモックアップ) を作成することですが、今のままでは新しいユーザーの情報を受け取っても保存する場所がないので、いきなりページを作成するわけにはいきません。ユーザー登録でまず初めにやることは、それらの情報を保存するためのデータ構造を作成することです。
Railsでは、データモデルで使用するデフォルトのデータ構造のことをモデルと呼びます (1.2.6で言うMVCのMのことです)。Railsでは、データを永続化するデフォルトの解決策として、データベースを使用してデータを長期間保存します。また、データベースとやりとりするデフォルトのRailsライブラリはActive Recordと呼ばれます1。Active Recordは、データオブジェクトの作成/保存/検索のためのメソッドを持っています。これらのメソッドを使用するのに、リレーショナルデータベースで使うSQL (Structured Query Language)2を意識する必要はありません。さらに、Railsにはマイグレーションという機能があります。データの定義をRubyで記述することができ、SQLのDDL (Data Definition Language)を新たに学ぶ必要がありません。Railsは、データストアの詳細からほぼ完全に私たちを切り離してくれます。本書では、SQLiteを開発環境で使い、またPostgreSQLを (Herokuでの) 開発環境で使います (1.4)。Railsは、本番アプリケーションですら、データの保存方法の詳細についてほとんど考える必要がないくらいよくできています。
6.1.1データベースの移行
4.4.5で扱ったカスタムビルドクラスのUserを思い出してください。このクラスは、nameとemailを属性に持つユーザーオブジェクトでした。このクラスは役に立つ例として提供されましたが、Railsにとって極めて重要な部分である永続性という要素が欠けていました。RailsコンソールでUserクラスのオブジェクトを作っても、コンソールからexitするとそのオブジェクトはすぐに消えてしまいました。この節での目的は、簡単に消えることのないユーザーのモデルを構築することです。
4.4.5のユーザークラスと同様に、nameとemailの2つの属性からなるユーザーをモデリングするところから始めましょう。後者のemailを一意のユーザー名として使用します3 (パスワードのための属性は6.3で扱います) 。リスト4.9では、以下のようにRubyのattr_accessorメソッドを使用しました。
class User
attr_accessor :name, :email
.
.
.
end
それとは対照的に、Railsでユーザーをモデリングするときは、属性を明示的に識別する必要がありません。上で簡潔に述べたように、Railsはデータを保存する際にデフォルトでリレーショナルデータベースを使用します。リレーショナルデータベースは、データ行で構成されるテーブルからなり、各行はデータ属性のカラム (列) を持ちます。たとえば、nameとemailを持つユーザーを保存するのであれば、nameとemailのカラムを持つusersテーブルを作成します (各行はひとりのユーザーを表します)。カラムをこのように名付けることによって、Active RecordでUserオブジェクトの属性を利用できるようになります。
それでは実際どのように動作するのか見てみましょう (ここまでの説明が抽象的でわかりにくいかもしれませんが、少しだけご辛抱願います。6.1.3から使用しているコンソールの例と、図6.3と図6.6にあるデータベースブラウザのスクリーンショットが理解を助けてくれるでしょう)。リスト5.29で、ユーザーコントローラ (とnewアクション) を作ったときに使った以下のコマンドを思い出してみてください。
$ rails generate controller Users new --no-test-framework
上のコマンドはコントローラを作成しましたが、同様にモデルを作成するコマンドとして、generate modelがあります。nameとemailの2つの属性を持つUserモデルを作成するコマンドをリスト6.1に示します。
$ rails generate model User name:string email:string
invoke active_record
create db/migrate/[timestamp]_create_users.rb
create app/models/user.rb
invoke rspec
create spec/models/user_spec.rb
(コントローラ名には複数形を使い、モデル名には単数形を用いるという慣習を頭に入れておいてください。コントローラはUsersでモデルはUserです)。name:stringやemail:stringオプションのパラメータを渡すことによって、データベースで使用したい2つの属性をRailsに伝えます。このときに、これらの属性の型情報も一緒に渡します (この場合はstring)。リスト3.4やリスト5.29でアクション名を使用して生成した例と比較してみてください。
リスト6.1にあるgenerateコマンドの結果のひとつとして、マイグレーションと呼ばれる新しいファイルが生成されます。マイグレーションは、データベースの構造をインクリメンタルに変更する手段を提供します。それにより、要求が変更された場合にデータモデルを適合させることができます。このUserモデルの例の場合、マイグレーションはモデル生成スクリプトによって自動的に作られました。リスト6.2に示したようにnameとemailの2つのカラムを持つusersテーブルを作成します (6.2.5と6.3で、マイグレーションを一から手動で作成する方法について説明します)。
usersテーブルを作るための) Userモデルのマイグレーション。db/migrate/[timestamp]_create_users.rb class CreateUsers < ActiveRecord::Migration
def change
create_table :users do |t|
t.string :name
t.string :email
t.timestamps
end
end
end
マイグレーションファイル名の先頭には、それが生成された時間のタイムスタンプが追加されます。以前はインクリメンタルな整数が追加されましたが、複数の開発者によるチームでは、複数のプログラマが同じ整数を持つマイグレーションを生成してしまい、コンフリクトを引き起こしていました。現在のタイムスタンプによる方法であれば、まったく同時にマイグレーションが生成されるという通常ではありえないことが起きない限り、そのようなコンフリクトは避けられます。
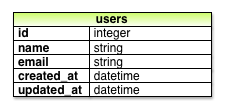
マイグレーション自体は、データベースに与える変更を定義したchangeメソッドの集まりです。リスト6.2の場合、changeメソッドはcreate_tableというRailsのメソッドを呼び、ユーザーを保存するためのテーブルをデータベースに作成します。create_tableメソッドはブロック変数を1つ持つブロック (4.3.2) を受け取ります。ここでは (“table”の頭文字を取って) tです。そのブロックの中で、create_tableメソッドはtオブジェクトを使って、今度はnameとemailカラムをデータベースに作成します。型はいずれもstringです4。モデル名は単数形 (User) ですが、テーブル名は複数形 (users) です。これはRailsで用いられる言葉の慣習を反映しています。モデルはひとりのユーザーを表すのに対し、データベースのテーブルは複数のユーザーから構成されます。ブロックの最後の行t.timestampsは特別なコマンドで、created_atとupdated_atという2つの「マジックカラム」を作成します。これらは、あるユーザーが作成または更新されたときに、その時刻を自動的に記録するタイムスタンプです (このマジックカラムの使用例を6.1.3から具体的に見ていきます)。 このマイグレーションで作られる完全なデータモデルを図6.2に示します。
マイグレーションは、以下のようにrakeコマンド (コラム 2.1) を使って実行することができます。これを「マイグレーションの適用 (migrating up)」と呼びます。
$ bundle exec rake db:migrate
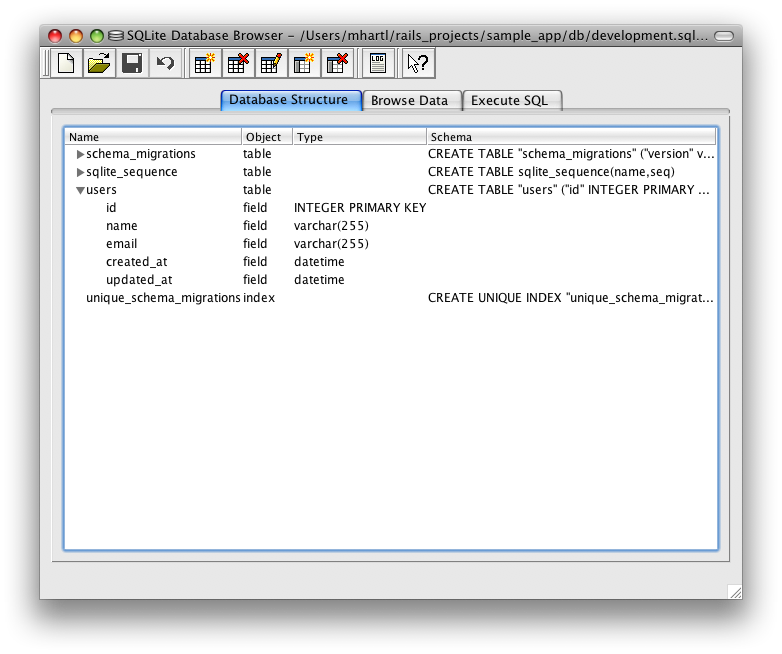
(2.2で、このコマンドを似たような状況で実行したことを思い出してみてください) 。初めてdb:migrateが実行されると、db/development.sqlite3という名前のファイルが生成されます。これはSQLite5データベースです。db/development.sqlite3ファイルを開くためのSQLite Database Browserという素晴らしいツールを使って、データベースの構造を詳しく参照することができます (図6.3)。図6.2の表と比べてみてください。図6.3の中にidというマイグレーションのときに説明されなかったカラムの存在に気づいたかもしれません。2.2で簡単に説明したとおり、このカラムは自動的に作成され、Railsが各行を一意に識別するために使用します。
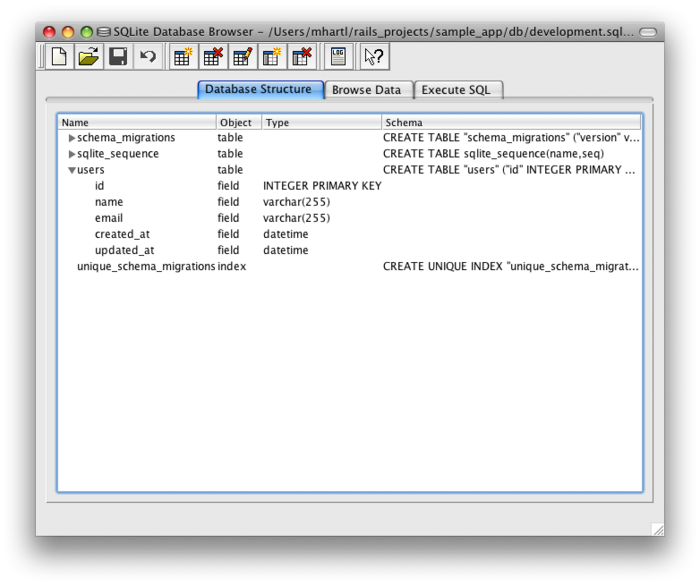
usersテーブル(拡大)Railsチュートリアルで使用されているものすべてを含め、ほとんどのマイグレーションが可逆です。これは、db:rollbackというRakeタスクで変更を取り消せることを意味します。これを“マイグレーションの取り消し (migrate down)”と呼びます。
$ bundle exec rake db:rollback
(コラム 3.2では、マイグレーションを元に戻すための便利なテクニックを他にも紹介しています)。上のコマンドでは、データベースからusersテーブルを削除するためにdrop_tableコマンドを内部で呼び出しています。これがうまくいくのは、changeメソッドはdrop_tableがcreate_tableの逆であることを知っているからです。つまり、ロールバック用の逆方向マイグレーションを簡単に導くことができるのです。あるカラムを削除するような不可逆なマイグレーションの場合は、changeメソッドの代わりに、upとdownのメソッドを別々に定義する必要があります。詳細については、Railsガイドの「Active Record マイグレーション」を参照してください。
もし今の時点でデータベースのロールバックを実行していた場合は、先に進む前にもう一度以下のようにマイグレーションを適用して元に戻してください。
$ bundle exec rake db:migrate
6.1.2modelファイル
これまで、リスト6.1のUserモデルの作成によってどのように (リスト6.2の) マイグレーションファイルが作成されるかを見てきました。そして図6.3でこのマイグレーションを実行した結果を見ました。usersテーブルを作成することで、development.sqlite3という名のファイルを更新し、id、name、email、created_at、updated_atを作成しました。リスト6.1ではモデル自体も作成しました。この節では、以後これらを理解することに専念します。
まず、app/models/ディレクトリにあるuser.rbファイルに書かれたUserモデルのコードを見てみましょう。これは控えめに言ってもとてもよくまとまっています (リスト6.3)
app/models/user.rb class User < ActiveRecord::Base
end
4.4.2で行ったことを思い出してみましょう。class User < ActiveRecord::Baseという構文で、UserクラスはActiveRecord::Baseを継承するので、Userモデルは自動的にActiveRecord::Baseクラスのすべての機能を持ちます。もちろん、この継承の知識は、ActiveRecord::Baseに含まれるメソッドなどについて知らなければ何の役にも立ちません。それらの知識の一部についてこれから説明します。
6.1.3ユーザーオブジェクトを作成する
第4章と同じく、Railsコンソールを使用してデータモデルを調べてみましょう。現時点ではデータベースを変更したくないので、コンソールをサンドボックスモードで起動します。
$ rails console --sandbox
Loading development environment in sandbox
Any modifications you make will be rolled back on exit
>>
"Any modifications you make will be rolled back on exit" (ここで行ったすべての変更は終了時にロールバックされます) というメッセージにわかりやすく示されているように、コンソールをサンドボックスで起動すると、そのセッションで行ったデータベースへの変更をコンソールの終了時にすべて “ロールバック” (取り消し) してくれます。
4.4.5のコンソールセッションではUser.newで新しいユーザーオブジェクトを生成しましたが、リスト4.9のexample_userファイルを明示的にrequireするまでこのオブジェクトにはアクセスできませんでした。しかし、モデルを使うと状況は異なります。4.4.4で見たように、Railsコンソールは起動時にRailsの環境を自動的に読み込み、その環境にはモデルも含まれます。つまり、新しいユーザーオブジェクトを作成するときに余分な作業を行わずに済むということです。
>> User.new
=> #<User id: nil, name: nil, email: nil, created_at: nil, updated_at: nil>
上の出力は、ユーザーオブジェクトをコンソール用に出力したものです。
User.newを引数なしで呼んだ場合は、すべての属性がnilのオブジェクトを返します。4.4.5では、オブジェクトの属性を設定するための初期化ハッシュ (hash) を引数に取るように、Userクラスの例 (example_user.rb) を設計しました。この設計は、同様の方法でオブジェクトを初期化するActive Recordの設計に基づいています。
>> user = User.new(name: "Michael Hartl", email: "mhartl@example.com")
=> #<User id: nil, name: "Michael Hartl", email: "mhartl@example.com",
created_at: nil, updated_at: nil>
上のように、nameとemail属性が期待どおり設定されていることがわかります。
開発ログ (log/development.log) をtail -fしたまま上を実行していた場合、実行後に新しい行が何も表示されないことに気付いた方もいると思います。これは、User.newを実行しても単にRubyオブジェクトをメモリ上に作成するだけで、データベースにはアクセスしないためです。このユーザーオブジェクトをデータベースに実際に保存するには、user変数に対してsaveメソッドを呼びます。
>> user.save
=> true
saveメソッドは、成功すればtrueを、失敗すればfalseを返します (現状では、保存はすべて成功するはずです。失敗する場合については6.2で説明します)。 保存すると、SQLコマンドのINSERT INTO "users"という行が開発ログに追加出力されることがすぐに確認できます。Active Recordによって多数のメソッドが提供されているので、本書では生のSQLを書く必要がありません。従って、本書ではこれ以降はSQLコマンドについての説明を省略します。ただしそれでも、開発ログを監視することによってSQLについて多くのことを学ぶことができるでしょう。
作成した時点でのユーザーオブジェクトは、id属性、マジックカラムであるcreated_at属性とupdated_at属性の値がいずれもnilであったことを思い出してください。saveメソッドを実行した後に何が変更されたのかを確認してみましょう。
>> user
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
idには1という値が代入され、一方でマジックカラムには現在の日時が代入されているのがわかります6。現在、作成と更新のタイムスタンプは同一ですが、6.1.5では異なる値になります。
4.4.5のUserクラスと同様に、Userモデルのインスタンスはドット記法を用いてその属性にアクセスすることができます7。
>> user.name
Michael Hartl
>> user.email
=> "mhartl@example.com"
>> user.updated_at
=> Mon, 11 Mar 2013 00:57:46 UTC +00:00
詳細は第7章でも説明しますが、上で見たようにモデルの生成と保存を2つのステップに分けておくと何かと便利です。しかし、Active RecordではUser.createでモデルの生成と保存を同時におこなう方法も提供されています。
>> User.create(name: "A Nother", email: "another@example.org")
#<User id: 2, name: "A Nother", email: "another@example.org", created_at:
"2013-03-11 01:05:24", updated_at: "2013-03-11 01:05:24">
>> foo = User.create(name: "Foo", email: "foo@bar.com")
#<User id: 3, name: "Foo", email: "foo@bar.com", created_at: "2013-03-11
01:05:42", updated_at: "2013-03-11 01:05:42">
User.createは、trueかfalseを返す代わりに、ユーザーオブジェクト自身を返すことに注目してください。返されたユーザーオブジェクトは (上の2つ目のコマンドにあるfooのように) 変数に代入することもできます。
destroyはcreateの逆です。
>> foo.destroy
=> #<User id: 3, name: "Foo", email: "foo@bar.com", created_at: "2013-03-11
01:05:42", updated_at: "2013-03-11 01:05:42">
奇妙なことに、destroyはcreateと同じようにそのオブジェクト自身を返しますが、その返り値を使用しても、もう一度destroyを呼ぶことはできません。そして、おそらくさらに奇妙なことに、destroyされたオブジェクトは以下のようにまだメモリ上に残っています。
>> foo
=> #<User id: 3, name: "Foo", email: "foo@bar.com", created_at: "2013-03-11
01:05:42", updated_at: "2013-03-11 01:05:42">
オブジェクトが本当に削除されたかどうかをどのようにして知ればよいでしょうか。そして、保存して削除されていないオブジェクトの場合、どうやってデータベースからユーザーを取得するのでしょうか。このあたりで、Active Recordでユーザーオブジェクトを検索する方法を学んでみましょう。
6.1.4ユーザーオブジェクトを検索する
Active Recordには、オブジェクトを検索するための方法がいくつもあります。これらの機能を使用して、過去に作成した最初のユーザーを探してみましょう。また、3番目のユーザー (foo) が削除されていることを確認しましょう。まずは存在するユーザーから探してみましょう。
>> User.find(1)
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
ここでは、User.findにユーザーのidを渡しています。その結果、Active Recordはそのidのユーザーを返します。
次に、id=3のユーザーがまだデータベースに存在するかどうかを確認してみましょう。
>> User.find(3)
ActiveRecord::RecordNotFound: Couldn't find User with ID=3
6.1.3で3番目のユーザーを削除したので、Active Recordはこのユーザーをデータベースの中から見つけることができませんでした。代わりに、findメソッドは例外 (exception) を発生します。例外はプログラムの実行時に何か例外的なイベントが発生したことを示すために使われます。この場合、存在しないActive Recordのidによって、findでActiveRecord::RecordNotFound例外8が発生しました。
一般的なfindメソッド以外に、Active Recordには特定の属性でユーザーを検索する方法もあります。
>> User.find_by_email("mhartl@example.com")
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
find_by_emailは、usersテーブルのemail属性に基づいてActive Recordが自動的に生成するメソッドです (ご想像どおり、Active Recordはfind_by_nameというメソッドも自動的に生成します)。 Rails 4.0以降では、属性を検索する場合には上のメソッドに代えてより普遍性の高いfind_byメソッドを使用することが推奨されています。このメソッドでは属性をハッシュ形式で渡します。
>> User.find_by(email: "mhartl@example.com")
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
これまでメールアドレスをユーザー名として使用してきたので、このようなfind関連メソッドは、ユーザーをサイトにログインさせる方法を学ぶときに役に立ちます (第7章)。ユーザー数が膨大になるとfind_byでは検索効率が低下するのではないかと心配する方もいるかもしれませんが、あせる必要はありません。この問題およびデータベースのインデックスを使った解決策については6.2.5で扱います。
ユーザーを検索する一般的な方法をあと少しだけご紹介して、この節を終わりにすることにしましょう。まず初めにfirstメソッドです。
>> User.first
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
読んで字のごとく、firstは単にデータベースの最初のユーザーを返します。次はallメソッドです。
>> User.all
=> [#<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">,
#<User id: 2, name: "A Nother", email: "another@example.org", created_at:
"2013-03-11 01:05:24", updated_at: "2013-03-11 01:05:24">]
期待どおり、allはデータベースのすべてのユーザーの配列 (4.3.1) を返します。
6.1.5ユーザーオブジェクトを更新する
いったんオブジェクトを作成すれば、今度は何度でも更新したくなるものです。基本的な更新の方法は2つです。ひとつは、4.4.5でやったように属性を個別に代入する方法です。
>> user # ユーザーの属性を保持している
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",
created_at: "2013-03-11 00:57:46", updated_at: "2013-03-11 00:57:46">
>> user.email = "mhartl@example.net"
=> "mhartl@example.net"
>> user.save
=> true
変更をデータベースに保存するために最後にsaveを実行する必要があることを忘れないでください。保存を行わずにreloadを実行すると、データベースの情報を元にオブジェクトを再読み込みするので、以下のように変更が取り消されます。
>> user.email
=> "mhartl@example.net"
>> user.email = "foo@bar.com"
=> "foo@bar.com"
>> user.reload.email
=> "mhartl@example.net"
今ユーザーを更新しました。6.1.3で約束したように、マジックカラムの更新日時が更新されました。
>> user.created_at
=> "2013-03-11 00:57:46"
>> user.updated_at
=> "2013-03-11 01:37:32"
属性を更新するもうひとつの方法は、update_attributesを使うものです。
>> user.update_attributes(name: "The Dude", email: "dude@abides.org")
=> true
>> user.name
=> "The Dude"
>> user.email
=> "dude@abides.org"
update_attributesメソッドは属性のハッシュを受け取り、成功時には更新と保存を続けて同時に行います (保存に成功した場合はtrueを返します)。ただし、検証に1つでも失敗すると、update_attributesの呼び出しは失敗します。たとえば、6.3で実装する、パスワードをレコードに保存することを要求すると検証は失敗します。特定の属性のみを更新する必要がある場合は、以下のようにupdate_attributeを単発で使用して制限を回避する必要があります。
>> user.update_attribute(:name, "The Dude")
=> true
>> user.name
=> "The Dude"
6.2ユーザーを検証する
ついに、6.1で作成したUserモデルに、アクセス可能なnameとemail属性が与えられました。しかし、これらの属性はどんな値でも取ることができてしまいます。現在は (空文字を含む) あらゆる文字列が有効です。名前とメールアドレスには、もう少し何らかの制限があってよいはずです。たとえば、nameは空であってはならず、emailはメールアドレスのフォーマットに従う必要があります。さらに、メールアドレスをユーザーがログインするときの一意のユーザー名として使おうとしているので、メールアドレスがデータベース内で重複することのないようにする必要もあります。
要するに、nameとemailにあらゆる文字列を許すのは避けるべきです。これらの属性値には、何らかの制約を与える必要があります。Active Recordでは検証 (バリデーション: validation) を使用してそのような制約を与えることができます。ここでは、よく使われるケースのうちのいくつかについて説明します。それらは存在性 (presence)の検証、長さ (length)の検証、フォーマット (format)の検証、一意性 (uniqueness)の検証です。6.3.4では、よく使われる最終検証として確認 (confirmation)を追加します。7.3では、ユーザーが制約に違反したときに、検証機能によって自動的に表示される有用なエラーメッセージをお見せします。
6.2.1最初のユーザーテスト
サンプルアプリケーションの他の機能と同様、Userモデルへの検証の追加もテスト駆動開発 (TDD) で行います。今回はUserモデルを作成したときに
--no-test-framework
(リスト5.29の例とは異なり) 上のフラグを渡さなかったので、リスト6.1のコマンドでは、モデル作成時に、ユーザーをテストするための初期specも同時に生成しています。ただし、生成された初期specは、実質的には空の状態です (リスト6.4)。
spec/models/user_spec.rb require 'spec_helper'
describe User do
pending "add some examples to (or delete) #{__FILE__}"
end
上のコードではpendingメソッドだけが置かれており、何か意味のあるコードでspecを埋めるように促しています。このコードの効果は、空のテスト用データベースを用意してUserモデルのspecを実行することで確認できます。
$ bundle exec rake db:migrate
$ bundle exec rake db:test:prepare
$ bundle exec rspec spec/models/user_spec.rb
*
Finished in 0.01999 seconds
1 example, 0 failures, 1 pending
Pending:
User add some examples to (or delete)
/Users/mhartl/rails_projects/sample_app/spec/models/user_spec.rb
(Not Yet Implemented)
多くのシステムでは、pendingのspecはコマンドライン上で黄色で表示されます。黄色は、成功 (緑) と失敗 (赤) の中間を意味します。
環境を整えるためにテスト環境用データベースを作成するコマンドを実行するのはこれが初めてです。
$ bundle exec rake db:test:prepare
上のコマンドは、単に開発データベースのデータモデルdb/development.sqlite3がテストデータベースdb/test.sqlite3に反映されるようにするものです。マイグレーションの後でたまにRakeタスクが実行できなくなることがあり、多くの人がこれに戸惑います。さらに、テストデータベースはたまに壊れることがあるので、その場合はリセットが必要です。もしテストスイートが理由もなく壊れるようなことがあれば、rake db:test:prepareを実行して、この問題が解決するか確認してみてください。
デフォルトのspecのアドバイスに従い、リスト6.5に示したいくつかのRSpecの例に置き換えてみましょう。
:nameと:email属性のテスト。spec/models/user_spec.rb require 'spec_helper'
describe User do
before { @user = User.new(name: "Example User", email: "user@example.com") }
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
end
リスト5.28でも使用したbeforeブロックは前処理用で、各サンプルが実行される前にそのブロックの中のコードを実行します。この場合、User.newと初期化用の有効なハッシュを使って、新しい@userインスタンス変数を作成します。そして以下のコードは、
subject { @user }
5.3.4でpage変数を扱ったときと同じように、@userをテストサンプルのデフォルトのsubjectとして設定します。
リスト6.5の2つのサンプルは、name属性とemail属性の存在をテストします。
it { should respond_to(:name) }
it { should respond_to(:email) }
Userオブジェクトがname属性を持っていない場合、beforeブロックの中で例外を投げるので、一見、これらのテストが冗長に思えるかもしれません。しかし、これらのテストを追加することで、user.nameやuser.emailが正しく動作することを保証できます (beforeブロック内では、ただ属性のハッシュをnewに渡せるかどうかをテストしているだけです)。また、モデルの属性をテストすることは良い習慣です。なぜなら、モデルの属性についてテストをすることで、そのモデルが応答すべきメソッドの一覧が一目で分かるからです。
そして、このテストで使われているrespond_toメソッドは、Rubyのrespond_to?メソッドを暗黙的に使っています。respond_to?メソッドは、シンボルを1つ引数として受け取り、そのシンボルが表すメソッドまたは属性に対して、オブジェクトが応答する場合はtrueを返し、応答しない場合はfalseを返します。
$ rails console --sandbox
>> user = User.new
>> user.respond_to?(:name)
=> true
>> user.respond_to?(:foobar)
=> false
(4.2.3でも説明したとおり、Rubyではtrue/falseの真偽値を返すメソッド名の末尾に?記号を置く慣習があることを思い出してください)。これらのテストは、RSpecで使われる論理値の慣習に依存しています。以下のコードは、
@user.respond_to?(:name)
以下のRSpecのコードでテストできます。
it "should respond to 'name'" do
expect(@user).to respond_to(:name)
end
ここでは、subject { @user }と記述してあるので、5.3.4で紹介したときと同様、@userを使わずに以下のように書くことができます。
it { should respond_to(:name) }
このようなテストが行えるので、新しい属性やメソッドをUserモデルに一時的に追加してテスト駆動開発を行うことができます。さらに、すべてのUserオブジェクトがこれらのメソッドに応答する必要があるという仕様もここで明らかになりました。
rake db:test:prepareを実行してテスト環境用データベースを用意したので、テストはパスするはずです。
$ bundle exec rspec spec/
6.2.2プレゼンスを検証する
おそらく最も基本的な検証 (validation) はプレゼンス (存在性) です。これは単に、与えられた属性が存在することを検証します。たとえばこの節では、ユーザーがデータベースに保存される前にnameとemailフィールドの両方が存在することを保証します。7.3.3では、この要求を新しいユーザーを作るためのユーザー登録フォームにまで徹底させる方法を確認します。
最初にname属性の存在を確認するテストを行いましょう。テスト駆動開発の最初のステップは失敗するテスト (3.2.1) を書くことですが、今回は、適切なテストを書くための検証事項についてまだ十分に理解していないので、まず最初に検証を書きます。検証については、コンソールを使って理解することにします。次に、その検証をコメントアウトし、失敗するテストを書き、そして検証のコメントアウトを解除することで、そのテストをパスさせられるかどうかを確認します。この手続きは、このような単純なテストでは、大げさで気取ったものに感じられるかもしれません。しかし著者はこれまでに、実際には見当違いなことをテストしている「単純な」テストを山ほど見てきました。テスト駆動開発を慎重に進めることは、結局は「私たちが正しい事項をテストしている」という自信を得る為の唯一の方法なのです。(上で紹介したコメントアウトのテクニックは、コードはあってもテストがどこにもないようなひどいアプリケーションを急いで救出するときにも役に立ちます)。
name属性の存在を検査する方法は、リスト6.6に示したとおり、validatesメソッドにpresence: trueという引数を与えて使うことです。presence: trueという引数は、要素がひとつのオプションハッシュです。4.3.4のようにメソッドの最後の引数としてハッシュを渡す場合、波括弧を付けなくても問題ありません (5.1.1でも説明したように、Railsのオプションハッシュは繰り返し登場するテーマです)。
name属性の存在を検証する。app/models/user.rb class User < ActiveRecord::Base
validates :name, presence: true
end
リスト6.6は一見魔法のように見えるかもしれませんが、validatesは単なるメソッドです。括弧を使用してリスト6.6を同等のコードに書き換えたものを以下に示します。
class User < ActiveRecord::Base
validates(:name, presence: true)
end
コンソールを起動して、Userモデルに検証を追加した効果を見てみましょう9。
$ rails console --sandbox
>> user = User.new(name: "", email: "mhartl@example.com")
>> user.save
=> false
>> user.valid?
=> false
user.saveはfalseを返しました。これは保存に失敗したことを意味します。最後のコマンドは、valid?メソッドで、オブジェクトがひとつ以上の検証に失敗したときにfalseを返します。すべての検証がパスした場合はtrueを返します。今回の場合、検証がひとつしかないので、どの検証が失敗したかわかります。しかし、失敗したときに作られるerrorsオブジェクトを使って確認すれば、さらに便利です。
>> user.errors.full_messages
=> ["Name can't be blank"]
(このエラーメッセージから、Railsが属性の存在性を検査するときにblank?メソッド (4.4.3の終わりに登場) を使用していることが推察できます。)
次は失敗するテストです。最初に、テストが失敗することを確認するために、この時点 (リスト6.7) でいったん検証をコメントアウトしてみましょう。
app/models/user.rb class User < ActiveRecord::Base
# validates :name, presence: true
end
最初の段階の検証テストをリスト6.8に示します。
name属性の検証に対する、失敗するテスト。spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com")
end
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
it { should be_valid }
describe "when name is not present" do
before { @user.name = " " }
it { should_not be_valid }
end
end
1番目の新しいテスト例は、単なる健全性チェックです。これを使用して、まず@userというsubjectが有効かどうかを確認します。
it { should be_valid }
上のコードは6.2.1で見た別のRSpecの真偽値の慣習を示すサンプルです。あるオブジェクトが、真偽値を返すfoo?というメソッドに応答するのであれば、それに対応するbe_fooというテストメソッドが (自動的に) 存在します。この場合、以下のメソッド呼び出しの結果をテストすることができます。
@user.valid?
上の呼び出しの結果を、以下のコードでテストできます。
it "should be valid" do
expect(@user).to be_valid
end
さっきと同様にsubject { @user }があるので、上のコードは@userを使わずに以下のように書くことができます。
it { should be_valid }
2番目のテストは、まずユーザーのnameに無効な値 (blank) を設定し、@userオブジェクトの結果も無効になることをテストして確認します。
describe "when name is not present" do
before { @user.name = " " }
it { should_not be_valid }
end
ユーザーのnameに無効な値 (blank) を設定するにはbeforeブロックを使います。次にユーザーオブジェクトの結果が無効であることを確認します。
この時点でテストが失敗することを確認してください。
$ bundle exec rspec spec/models/user_spec.rb
...F
4 examples, 1 failure
それではここで、テストにパスするために検証部分のコメントアウトを解除しましょう (つまり、リスト6.7をリスト6.6に戻します)。
$ bundle exec rspec spec/models/user_spec.rb
....
4 examples, 0 failures
もちろん、今度はメールアドレスの存在性も検証しましょう。このテスト (リスト6.9) は、name属性のテストと似ています。
email属性の存在性のテスト。spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
describe "when email is not present" do
before { @user.email = " " }
it { should_not be_valid }
end
end
以下のリスト6.10に示すように、メールアドレス検証の実装も名前の検証と実質的に同じです。
name属性とemail属性の存在性を検証する。app/models/user.rb class User < ActiveRecord::Base
validates :name, presence: true
validates :email, presence: true
end
これですべてのテストにパスするはずです。これで、存在性の検証は完成しました。
6.2.3長さを検証する
各ユーザーは、Userモデル上に名前を持つことを強制されるようになりました。しかし、これだけでは十分ではありません。ユーザーの名前はサンプルWebサイトに表示されるものなので、名前の長さにも制限を与える必要があります。6.2.2で既に同じような作業を行ったので、この実装は簡単です。
まずはテストを作成します。最長のユーザー名の長さに科学的な根拠はありませんので、単に50という上限として手頃な値を使うことにします。つまりここでは、51文字の名前は長すぎることを検証します (リスト6.11)。
nameの長さ検証のテスト。spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
describe "when name is too long" do
before { @user.name = "a" * 51 }
it { should_not be_valid }
end
end
リスト6.11では、51文字の文字列を簡単に作るために “文字列のかけ算” を使いました。結果をコンソール上で確認できます。
>> "a" * 51
=> "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"
>> ("a" * 51).length
=> 51
今の時点ではリスト6.11のテストは失敗するはずです。これをパスさせるためには、長さを強制するための検証の引数について知っておく必要があります。:maximumパラメータと共に用いられる:lengthは、長さの上限を強制します (リスト6.12)。
name属性の長さの検証を追加する。app/models/user.rb class User < ActiveRecord::Base
validates :name, presence: true, length: { maximum: 50 }
validates :email, presence: true
end
これでテストにパスするはずです。パスしたテストスイートを流用して、今度は少し難しい、メールアドレスのフォーマット検証作業に取りかかりましょう。
6.2.4フォーマットを検証する
name属性の検証には、空文字でない、名前が51文字未満であるという最小限の制約しか与えていませんでした。email属性の場合は、もっと厳重な要求を満たさなければなりません。これまでは空のメールアドレスのみを禁止してきましたが、ここではメールアドレスにおなじみのパターンuser@example.comに合っているかどうかも確認することを要求します。
なお、ここで使用するテストや検証は、形式がひとまず有効なメールアドレスを受け入れ、形式があからさまに無効なものを拒否するだけであり、すべての場合を網羅したものではないという点に注意してください。最初に、有効なメールアドレスと無効なメールアドレスのコレクションに対するテストを行いましょう。このコレクションを作るために、以下のコンソールセッションに示したような、文字列の配列を簡単に作れる%w[]という便利なテクニックを知っておくと良いでしょう。
>> %w[foo bar baz]
=> ["foo", "bar", "baz"]
>> addresses = %w[user@foo.COM THE_US-ER@foo.bar.org first.last@foo.jp]
=> ["user@foo.COM", "THE_US-ER@foo.bar.org", "first.last@foo.jp"]
>> addresses.each do |address|
?> puts address
>> end
user@foo.COM
THE_US-ER@foo.bar.org
first.last@foo.jp
eachメソッドを使ってaddresses配列の各要素を繰り返し取り出しました (4.3.2)。このテクニックを学んだことで、基本となるメールアドレスフォーマット検証のテストを書く準備が整いました (リスト6.13)。
spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
describe "when email format is invalid" do
it "should be invalid" do
addresses = %w[user@foo,com user_at_foo.org example.user@foo.
foo@bar_baz.com foo@bar+baz.com]
addresses.each do |invalid_address|
@user.email = invalid_address
expect(@user).not_to be_valid
end
end
end
describe "when email format is valid" do
it "should be valid" do
addresses = %w[user@foo.COM A_US-ER@f.b.org frst.lst@foo.jp a+b@baz.cn]
addresses.each do |valid_address|
@user.email = valid_address
expect(@user).to be_valid
end
end
end
end
既に述べたとおり、上のテストはすべてを盛り込んだものではありませんが、一般的に有効なメールアドレスの形式であるuser@foo.COM、THE_US-ER@foo.bar.org (大文字、アンダースコア、複合ドメイン) 、first.last@foo.jp (一般的な企業のユーザー名「名.姓」と、2文字のトップレベルドメイン「jp」) を、いくつかの無効な形式と共に確認します。
メールアドレスのフォーマット検証を行うアプリケーションコードでは、validatesメソッドの:format引数に、フォーマットを定義するための正規表現 (regular expression) (regexとも書きます) を与えます (リスト6.14)。
app/models/user.rb class User < ActiveRecord::Base
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX }
end
正規表現VALID_EMAIL_REGEXは定数です。大文字で始まる名前はRubyでは定数を意味します。以下のコードは、
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX }
このパターンに一致するメールアドレスだけが有効であることをチェックします (VALID_EMAIL_REGEXは大文字で始まるので、Rubyの定数として扱われ、値は変更できません)。
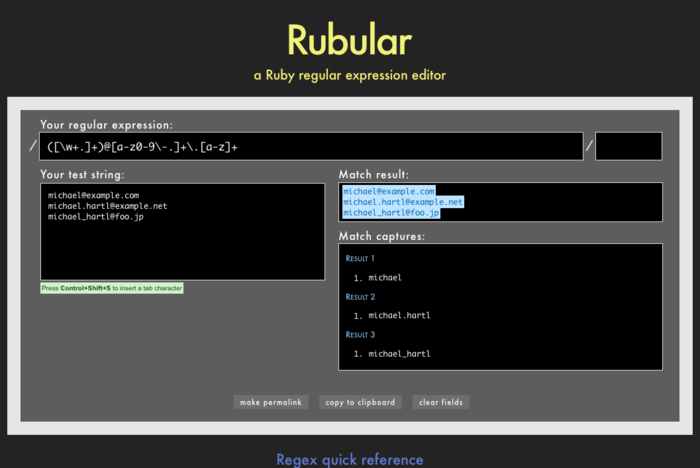
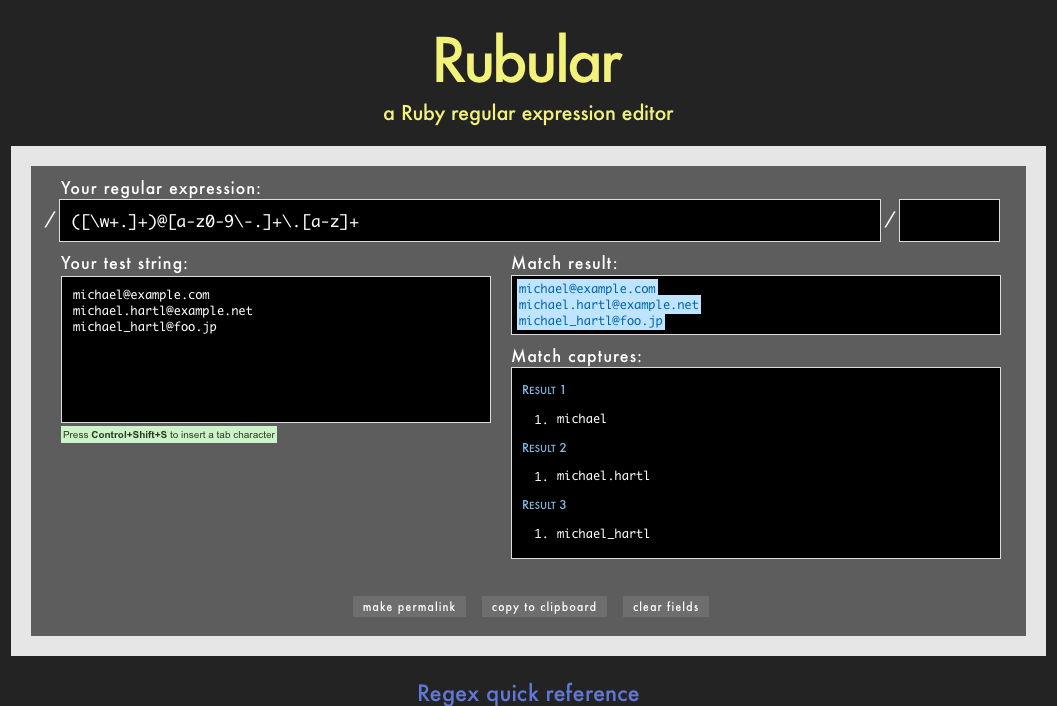
ところで、この正規表現パターンはどうやって作ればよいのでしょうか。正規表現は簡潔な (読めないという人もいますが) テキストパターンマッチング言語から成ります。正規表現を組み立てることを学ぶのはそれだけでひとつの技術分野であり、手短に説明するのは簡単ではありませんが、ともあれ最初の説明のためにVALID_EMAIL_REGEXをビットサイズの部品に分解しました (表6.1)10。本当に正規表現を学びたいなら、素晴らしい正規表現エディタであるRubular (図6.4) が必要不可欠です11。RubularのWebサイトは、正規表現を作るための美しく対話的なインターフェイスを持っています。また、手軽な正規表現のクイックリファレンスにもなります。Rubularのサイトをブラウザで開き、表6.1の表現をひとつずつ入力して結果を確かめながら正規表現を学ぶことをぜひともお勧めします。正規表現について学んだことがなくても、Rubularを使えば2〜3時間ほどで慣れることができます (注: リスト6.14の正規表現をRubularで使う場合、冒頭の\Aと末尾の\zの文字は含めないでください)。
| 表現 | 意味 |
|---|---|
| /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i | (完全な正規表現) |
| / | 正規表現の開始を示す |
| \A | 文字列の先頭 |
| [\w+\-.]+ | 英数字、アンダースコア (_)、プラス (+)、ハイフン (-)、ドット (.) のいずれかを少なくとも1文字以上繰り返す |
| @ | アットマーク |
| [a-z\d\-.]+ | 英小文字、数字、ハイフン、ドットのいずれかを少なくとも1文字以上繰り返す |
| \. | ドット |
| [a-z]+ | 英小文字を少なくとも1文字以上繰り返す |
| \z | 文字列の末尾 |
| / | 正規表現の終わりを示す |
| i | 大文字小文字を無視するオプション |
ところで、公式標準によるとメールアドレスに完全に一致する正規表現は存在するのだそうです。しかし、苦労して導入するほどの甲斐はありません。リスト6.14の例は問題なく動作しますし、おそらく公式のものより良いでしょう12。上の正規表現には少しだけ残念な点があります。foo@bar..comのようなドットの連続を誤りとして検出できません。この問題の修正は、演習問題に回します (6.5)。
{kind=link}
{kind=link}
{kind=link}
これでテストはすべてパスするはずです(実際、この有効なメールアドレスのテストはこれまでいつもパスしてきました。正規表現のプログラミングは間違いが起こりやすいことで有名なので、ここで行なっている有効なメールアドレスのテストは、主としてVALID_EMAIL_REGEXに対する形式的な健全性チェックに過ぎません)。残る制約は、メールアドレスが一意であることを強制するものだけとなりました。
6.2.5一意性を検証する
メールアドレスの一意性を強制するために (ユーザー名として使うために)、validatesメソッドの:uniqueオプションを使います。ただしここで重大な警告があります。以下の文面は流し読みせず、必ず注意深く読んでください。
今回もいつものようにテストを作成するところから始めます。モデルのテストではこれまで、主にUser.newを使ってきました。このメソッドは単にメモリ上にRubyのオブジェクトを作るだけです。しかし、一意性のテストのためには、メモリ上だけではなく、実際にレコードをデータベースに登録する必要があります13。(最初の段階の) 重複メールアドレスのテストをリスト6.15に示します。
spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
describe "when email address is already taken" do
before do
user_with_same_email = @user.dup
user_with_same_email.save
end
it { should_not be_valid }
end
end
上のコードは、@userと同じメールアドレスのユーザーを事前に作成する手法です。今回は、同じ属性のユーザーを作るために、@user.dupを使っています。同じ属性のユーザーが保存された後では、元の@userと同じメールアドレスが既にデータベース内に存在しているため、@userは無効になります。
先ほどのリスト6.15のテストは、リスト6.16のコードを用いてパスさせることができます。
app/models/user.rb class User < ActiveRecord::Base
.
.
.
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX },
uniqueness: true
end
実装の途中ですが、ここでひとつ補足します。通常、メールアドレスでは大文字小文字が区別されません。すなわち、foo@bar.comはFOO@BAR.COMやFoO@BAr.coMと書いても扱いは同じです。従って、メールアドレスの検証ではこのような場合も考慮する必要があります14 。リスト6.17のコードでは、大文字小文字を区別せずにテストしています。
spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com")
end
.
.
.
describe "when email address is already taken" do
before do
user_with_same_email = @user.dup
user_with_same_email.email = @user.email.upcase
user_with_same_email.save
end
it { should_not be_valid }
end
end
上のコードではStringのupcaseメソッドを使っています (4.3.2)。このテストは最初のメールアドレスの重複テストと同じことをしていますが、大文字に変換したメールアドレスを使っている点が異なります。もしこのテストが少し抽象的すぎると感じるなら、Railsコンソールを起動して確認しましょう。
$ rails console --sandbox
>> user = User.create(name: "Example User", email: "user@example.com")
>> user.email.upcase
=> "USER@EXAMPLE.COM"
>> user_with_same_email = user.dup
>> user_with_same_email.email = user.email.upcase
>> user_with_same_email.valid?
=> true
現在の一意性検証では大文字小文字を区別しているため、user_with_same_email.valid?はtrueになります。しかし、ここではfalseになる必要があります。幸い、:uniquenessでは:case_sensitiveといううってつけのオプションが使用できます (リスト6.18)。
app/models/user.rb class User < ActiveRecord::Base
.
.
.
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false }
end
上のコードでは、単にtrueをcase_sensitive: falseで置き換えただけであることに注目してください。Railsはこの場合、:uniquenessをtrueと判断します。この時点で、アプリケーションは重要な警告と共にメールアドレスの一意性を強制し、テストスイートもパスするはずです。
一意性の警告
上で示した警告には、1つ小さな問題があります。
validates :uniquenessを使用しても、一意性は保証されません。
えっ?!いったい何が問題なのでしょうか。以下のシナリオを見てください。
- アリスはサンプルアプリケーションにユーザー登録します。メールアドレスはalice@wonderland.comです。
- アリスは誤って “Submit” を素早く2回クリックしてしまいます。そのためリクエストが2つ連続で送信されます。
- 次のようなことが順に発生します。リクエスト1は、検証にパスするユーザーをメモリー上に作成します。リクエスト2でも同じことが起きます。リクエスト1のユーザーが保存され、リクエスト2のユーザーも保存されます。
- この結果、一意性の検証が行われているにもかかわらず、同じメールアドレスを持つ2つのユーザーレコードが作成されてしまいます。
上のシナリオが信じがたいもののように思えるかもしれませんが、どうか信じてください。RailsのWebサイトでは、トラフィックが多いときにこのような問題が発生する可能性があるのです。幸い、解決策の実装は簡単です。実は、この問題はデータベースレベルでも一意性を強制するだけで解決します。具体的には、emailカラムにデータベースのインデックスを作成し、そのインデックスが一意であることを要求します。
emailインデックスを追加すると、データモデリングの変更が必要になります。Railsでは (6.1.1で見たように) マイグレーションでインデックスを追加します。6.1.1で、Userモデルを生成すると自動的に新しいマイグレーションが作成されたことを思い出してください (リスト6.2)。今回の場合は、既に存在するモデルに構造を追加するので、以下のようにmigrationジェネレーターを使用してマイグレーションを直接作成する必要があります。
$ rails generate migration add_index_to_users_email
ユーザー用のマイグレーションと異なり、メールアドレスの一意性のマイグレーションは未定義になっています。リスト6.19のように定義を記述する必要があります15。
db/migrate/[timestamp]_add_index_to_users_email.rb class AddIndexToUsersEmail < ActiveRecord::Migration
def change
add_index :users, :email, unique: true
end
end
上のコードでは、usersテーブルのemailカラムにインデックスを追加するためにadd_indexというRailsのメソッドを使っています。インデックス自体は一意性を強制しませんが、オプションでunique: trueを指定することで強制できるようになります。
最後に、データベースをマイグレートします。
$ bundle exec rake db:migrate
(上のコマンドが失敗した場合は、実行中のサンドボックスのコンソールセッションを終了してみてください。そのセッションがデータベースをロックしてマイグレーションを妨げている可能性があります)。一意性を強制すると何が起きるかについて関心のある方は、db/schema.rbを開いてみると以下のような行があるはずです。
add_index "users", ["email"], name: "index_users_on_email", unique: true
残念なことに、メールアドレスの一意性を保証するためには、もう1つやらなければならないことがあります。それは、メールアドレスをデータベースに保存する前にすべての文字を小文字に変換することです。その理由は、データベースのアダプタが常に大文字小文字を区別するインデックスを使っているとは限らないからです16。これを行うにはコールバックというテクニックを利用します。コールバックとは、Active Recordオブジェクトが持続している間のどこかの時点で、Active Recordオブジェクトに呼び出してもらうメソッドです (詳しくはRailsガイドの「Active Recordコールバック」を参照してください)。今回の場合は、before_saveコールバックを使います。リスト6.20に示したように、ユーザーをデータベースに保存する前にemail属性を強制的に小文字に変換します。
app/models/user.rb class User < ActiveRecord::Base
before_save { self.email = email.downcase }
.
.
.
end
リスト6.20のコードは、before_saveコールバックにブロックを渡してユーザーのメールアドレスを設定します。設定されるメールアドレスは、現在の値をStringクラスのdowncaseメソッドを使って小文字バージョンにしたものです。このコードは少し上級者向けなので、今はただ、このコードが動作することを信じてください。それでは気の済まない方は、リスト6.16から一意性の検証部分をコメントアウトし、重複したメールアドレスを持つユーザーを試しに作成してみれば、エラーが発生するはずです (このテクニックについては8.2.1でもう一度取り上げます。そこではお勧めのメソッド参照方法の慣習について説明します)。リスト6.20のコード用テストの作成は演習に回します (6.5)。
これで、先に述べたアリスのシナリオはうまくいくようになります。データベースは、最初のリクエストに基づいてユーザーのレコードを保存しますが、2度目の保存は一意性の制約に反するので拒否します (Railsのログにエラーが出力されますが、害は生じません。ここで発生したActiveRecord::StatementInvalid例外を実際にキャッチすることもできますが、このチュートリアルでは解説しません)。インデックスをemail属性に追加したことで、6.1.4で述べた2番目の目標 (エントリ多数の場合の検索効率向上) も達成されます。これは、find_byの効率の問題がインデックスによって解決されたためです (コラム 6.2)。
6.3セキュアなパスワードを追加する
この節では、ユーザーに最後の属性を追加します。セキュアパスワードは、サンプルアプリケーションでユーザーを認証するために使用します。セキュアパスワードという手法では、各ユーザーにパスワードとパスワードの確認を入力させ、それを (そのままではなく) 暗号化したものをデータベースに保存します。また、入力されたパスワードを使用してユーザーを認証する手段と、第8章で使用する、ユーザーがサイトにサインインできるようにする手段も提供します。
ユーザーの認証は、パスワードの送信、暗号化、データベース内の暗号化された値との比較という手順を踏みます。比較の結果が一致すれば、送信されたパスワードは正しいと認識され、そのユーザーは認証されます。ここで、生のパスワードではなく、暗号化されたパスワード同士を比較していることに注目してください。こうすることで、生のパスワードをデータベースに保存するという危険なことをしなくてもユーザーを認証できます。これで、仮にデータベースの内容が盗まれたり覗き見されるようなことがあっても、パスワードの安全性が保たれます。
セキュアなパスワードの実装は、has_secure_passwordというRailsのメソッドを呼び出すだけでほとんど終わってしまいます (このメソッドはRails 3.1から導入されました)。このメソッド1つだけでセキュアなパスワードの実装がほとんど終わってしまうので、逆にこの機能を最初から手作りするのは簡単ではありません。6.3.2以降では、has_secure_passwordメソッドを早期に導入しておき、テストを新しく書くたびにこのメソッドを一時的にコメントアウトして、正しいテスト駆動開発を行うことをお勧めします。(スクリーンキャストは、このような一からの手作り開発手順を解説するのに向いています。この課題を十分に理解したい方は「Ruby on Railsチュートリアルのスクリーンキャスト (日本語版)」を参照してください)。
6.3.1暗号化されたパスワード
最初に、ユーザーのデータモデルに必要な変更を行います。具体的には、usersテーブルにpassword_digestカラムを追加します (図6.5)。なお、digestという言葉は暗号学的ハッシュ関数が用語の語源です。6.3.4の実装が動作するには、カラム名を正確にpassword_digestとする必要があります。パスワードを適切に暗号化することで、たとえ攻撃者によってデータベースからパスワードをコピーされてもWebサイトにサインインされることのないようにできます。
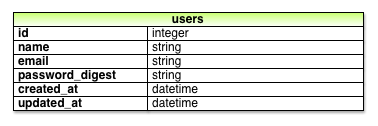
password_digest属性を追加する。ハッシュ関数には最新のbcryptを使用し、パスワードを不可逆的に暗号化してパスワードハッシュを作成します。サンプルアプリケーションでbcryptを使用するために、bcrypt-ruby gemをGemfileに追加します (リスト6.21)。
bcrypt-rubyをGemfileに追加する。 source 'https://rubygems.org'
ruby '2.0.0'
#ruby-gemset=railstutorial_rails_4_0
gem 'rails', '4.0.5'
gem 'bootstrap-sass', '2.3.2.0'
gem 'sprockets', '2.11.0'
gem 'bcrypt-ruby', '3.1.2'
.
.
.
次にbundle installを実行します。
$ bundle install
ユーザーはpassword_digestカラムにアクセスしなければならないので、リスト6.22に示すように、ユーザーオブジェクトはpassword_digestに応答する必要があります。
password_digestカラムがあることを確認するテスト。spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com")
end
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
it { should respond_to(:password_digest) }
.
.
.
end
このテストがパスするには、最初にpassword_digestカラム用の適切なマイグレーションを生成します。
$ rails generate migration \
add_password_digest_to_users password_digest:string
上のコマンドの最初の引数はマイグレーション名、次の引数は作成する属性の名前と型です (リスト6.1で最初にusersテーブルを生成したときのマイグレーションと比較してみてください)。マイグレーション名は自由に指定できますが、上のように末尾を_to_usersにしておくことをお勧めします。こうしておくと、usersテーブルにカラムを追加するマイグレーションがRailsによって自動的に作成されるからです。また、上のコマンドに2番目の引数を与えることで、リスト6.23のように完全なマイグレーションを構成するための情報をRailsに与えることができます。
password_digestカラムをusersテーブルに追加するマイグレーション。db/migrate/[ts]_add_password_digest_to_users.rb class AddPasswordDigestToUsers < ActiveRecord::Migration
def change
add_column :users, :password_digest, :string
end
end
上のコードでは、add_columnメソッドを使用してpassword_digest カラムをusersテーブルに追加しています。
以下のように開発データベースをマイグレーションしてテストデータベースを準備することで、リスト6.22の失敗するテストをパスすることができます。
$ bundle exec rake db:migrate
$ bundle exec rake db:test:prepare
$ bundle exec rspec spec/
6.3.2パスワードと確認
図6.1のモックアップに示したように、ユーザーにパスワードを確認させるようにしましょう。パスワードの確認入力は、入力ミスを減らすためにWebで広く使用されています。パスワード確認の強制はコントローラの階層でも行うことができますが、モデルの中でActive Recordを使用して制限を与えるのが慣習になっています。そのためには、password属性とpassword_confirmation属性をUserモデルに追加し、レコードをデータベースに保存する前に2つの属性が一致するように要求します。これまでに使用した属性と異なり、パスワード関連の属性は「仮想」にする点に注意してください。つまり、これらの属性は一時的にメモリ上に置き、データベースには保存されないようにします。6.3.4でも説明しますが、これらの仮想属性はhas_secure_passwordでは自動的に実装されます。
最初に、respond_toを使用してパスワードとパスワードの確認をリスト6.24のようにテストします。
password属性とpassword_confirmation属性をテストする。spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com",
password: "foobar", password_confirmation: "foobar")
end
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
it { should respond_to(:password_digest) }
it { should respond_to(:password) }
it { should respond_to(:password_confirmation) }
it { should be_valid }
.
.
.
end
上のコードでは、以下のようにUser.newハッシュの初期化に:passwordと:password_confirmationを追加していることに注目してください。
before do
@user = User.new(name: "Example User", email: "user@example.com",
password: "foobar", password_confirmation: "foobar")
end
パスワードは空欄であってはならないので、パスワードの存在確認テストを別に追加します。
describe "when password is not present" do
before do
@user = User.new(name: "Example User", email: "user@example.com",
password: " ", password_confirmation: " ")
end
it { should_not be_valid }
end
パスワードの不一致テストはこのすぐ後に追加するので、上のコードではパスワードとパスワードの確認を両方とも空欄にすることでパスワードの存在確認テストを行なっています。
パスワードとパスワードの確認が一致するかどうかもテストする必要があります。パスワードが一致する場合については既にit { should be_valid }で確認できるので、次は以下のように不一致の場合のテストを追加します。
describe "when password doesn't match confirmation" do
before { @user.password_confirmation = "mismatch" }
it { should_not be_valid }
end
ここまでのすべてを盛り込んだ失敗するテストをリスト6.25に示します。
spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com",
password: "foobar", password_confirmation: "foobar")
end
subject { @user }
it { should respond_to(:name) }
it { should respond_to(:email) }
it { should respond_to(:password_digest) }
it { should respond_to(:password) }
it { should respond_to(:password_confirmation) }
it { should be_valid }
.
.
.
describe "when password is not present" do
before do
@user = User.new(name: "Example User", email: "user@example.com",
password: " ", password_confirmation: " ")
end
it { should_not be_valid }
end
describe "when password doesn't match confirmation" do
before { @user.password_confirmation = "mismatch" }
it { should_not be_valid }
end
end
上のリスト6.25のテストは、リスト6.26に示したようにコードにたった1行追加するだけでパスするようになります。
app/models/user.rb class User < ActiveRecord::Base
.
.
.
has_secure_password
end
以下の1行を追加するだけで、
has_secure_password
現在のパスワード関連テストがすべてパスするようになり、他の多くのテストにもパスするようになります。このメソッドがあまりに目覚しい働きをするので、この後のテストで赤から青に状態を変えるチュートリアルが逆にやりにくくなってしまいます。そこで、一時的にコメントアウトしておいてください (リスト6.27).
has_secure_passwordをコメントアウトする。app/models/user.rb class User < ActiveRecord::Base
.
.
.
# has_secure_password
end
6.3.3ユーザー認証
パスワード機構というパズルの最後のひとかけらは、ユーザーをメールアドレスとパスワードに基いて取得する手段です。この作業は2つに分けるのが自然です。最初に、ユーザーをメールアドレスで検索します。次に、受け取ったパスワードでユーザーを認証します。この節のテストは、最後の1つを除いてすべてhas_secure_passwordメソッドによって実装できるので、リスト6.27でコメントアウトした行は実装中にコメント解除し、テストがパスするようにしてください。
最初の手順の実装は簡単です。6.1.4でも説明したように、find_byメソッドを使用すれば、受け取ったメールアドレスでユーザーを検索できます。
user = User.find_by(email: email)
次の手順は、authenticateメソッドを使用して、受け取ったパスワードがユーザーのパスワードと一致することを確認します。第8章では、以下のようなコードを使用して現在の (サインインしている) ユーザーを取得する予定です。
current_user = user.authenticate(password)
受け取ったパスワードがユーザーのパスワードと一致するとユーザーが返され、一致しない場合はfalseが返されます。
これまで同様、RSpecを使用してauthenticateメソッドへの要求内容を表現することができます。ただし、このテストはこれまでよりも高度な内容になるため、いくつかに分割して説明します。RSpecが初めての方は、この節を繰り返し読んでみてください。最初に、Userオブジェクトがauthenticateに応答することを要求します。
it { should respond_to(:authenticate) }
次に、パスワードが一致する場合と一致しない場合についてそれぞれ記述します。
describe "return value of authenticate method" do
before { @user.save }
let(:found_user) { User.find_by(email: @user.email) }
describe "with valid password" do
it { should eq found_user.authenticate(@user.password) }
end
describe "with invalid password" do
let(:user_for_invalid_password) { found_user.authenticate("invalid") }
it { should_not eq user_for_invalid_password }
specify { expect(user_for_invalid_password).to be_false }
end
end
上のコードで、beforeブロックはユーザーをデータベースに事前に保存します。これにより、find_byメソッドが動作するようになります。このメソッドをletメソッドで以下のようにテストします。
let(:found_user) { User.find_by(email: @user.email) }
これまでいくつかの演習でletメソッドを使用してきましたが、今回のようにチュートリアルの本文で言及するのはこれが初めてです。letメソッドの詳細についてはコラム 6.3を参照してください。
2つのdescribeブロックでは、@userとfound_userが一致する (パスワードが一致する) 場合と一致しない (パスワードが一致しない) 場合についてそれぞれテストします。コードで使用されているeqは、オブジェクト同士が同値であるかどうかを調べます (eqの内部では4.3.1で説明した二重等号演算子==を使用してオブジェクトが同値であるかどうかを確認しています)。以下のコードに注目してください。
describe "with invalid password" do
let(:user_for_invalid_password) { found_user.authenticate("invalid") }
it { should_not eq user_for_invalid_password }
specify { expect(user_for_invalid_password).to be_false }
end
上のコードではletがもう一度使用されており、さらにspecifyというメソッドも使用されています。実は、このspecifyはitと同義であり、itを使用すると英語として不自然な場合にこれで代用することができます。この場合、「it should not equal wrong user」(itはユーザーなど) とするのは英語として自然ですが、「user: user with invalid password should be false」は不自然であり、「specify: user with invalid password should be false」とすれば自然になります。
最後に、セキュリティの常道として、パスワードの長さ検証をテストします。以下のコードでは、パスワードは6文字以上であることを要求します。
describe "with a password that's too short" do
before { @user.password = @user.password_confirmation = "a" * 5 }
it { should be_invalid }
end
ここまでのテストをすべて集約したものをリスト6.28に示します。
authenticateメソッドをテストする。spec/models/user_spec.rb require 'spec_helper'
describe User do
before do
@user = User.new(name: "Example User", email: "user@example.com",
password: "foobar", password_confirmation: "foobar")
end
subject { @user }
.
.
.
it { should respond_to(:authenticate) }
.
.
.
describe "with a password that's too short" do
before { @user.password = @user.password_confirmation = "a" * 5 }
it { should be_invalid }
end
describe "return value of authenticate method" do
before { @user.save }
let(:found_user) { User.find_by(email: @user.email) }
describe "with valid password" do
it { should eq found_user.authenticate(@user.password) }
end
describe "with invalid password" do
let(:user_for_invalid_password) { found_user.authenticate("invalid") }
it { should_not eq user_for_invalid_password }
specify { expect(user_for_invalid_password).to be_false }
end
end
end
コラム 6.3で解説したように、letでは値がメモ化されます。これにより、リスト6.28にある、ネストしている最初のdescribeブロックはletでfind_byを使用してデータベースからユーザーを取得します。しかしその次のネストしているdescribeブロックは (メモ化された値を利用するので) データベースにアクセスしません。
6.3.4ユーザーがセキュアなパスワードを持っている
認証システムを最初からフル作成していたRails 3.0向けRailsチュートリアル17を参照いただくとわかるように、以前のバージョンのRailsでは、セキュアパスワードの実装は面倒で時間のかかる作業でした。しかし今では、Web開発者が認証システムというものを以前よりも深く理解するようになり、最新のRailsには認証システムも同梱されるようになりました。ここまで実装を進めてきたので、あとほんの数行を追加してセキュアパスワードの実装を完了し、テストスイートを緑色 (成功) にしましょう。
最初に、パスワードの長さ検証を行います。これには:minimumキーを使用しますが、これはリスト6.12で使用した:maximumキーから容易に想像がつきます。
validates :password, length: { minimum: 6 }
(パスワードの存在検証と確認はhas_secure_passwordによって自動的に追加されます。)
次に、password属性とpassword_confirmation属性を追加し、パスワードが存在することを要求し、パスワードとパスワードの確認が一致することを要求し、さらにauthenticateメソッドを使用して、暗号化されたパスワードとpassword_digestを比較してユーザーを認証するという多くの手順が必要です。この実装が唯一手間のかかる箇所ですが、最新のRailsではhas_secure_passwordを使用するだけでこれらの機能をすべて自由に利用できます。
has_secure_password
データベースにpassword_digestカラムを置くという条件さえ守れば、上のメソッドをモデルに追加するだけで新規ユーザーの作成と認証をセキュアにすることができます。
(has_secure_passwordの実装に興味のある方は、secure_password.rbのソースコードを参照してみるとよいでしょう。このソースコードには十分な解説があり、しかも読みやすくできています。そのコードに、以下の行があることに注目してください。
validates_confirmation_of :password,
if: lambda { |m| m.password.present? }
上のコードを実行するだけで、(Rails APIに記載されているように) password_confirmationという属性が作成されます。このコードにはpassword_digest属性の検証も含まれます。)
上の要素をリスト6.26で行われる存在確認と合わせて、リスト6.29に示したようにUserモデルを実装できます。セキュアなパスワードの実装はこれで完了です。
app/models/user.rb class User < ActiveRecord::Base
before_save { self.email = email.downcase }
validates :name, presence: true, length: { maximum: 50 }
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i
validates :email, presence: true,
format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false }
has_secure_password
validates :password, length: { minimum: 6 }
end
ここまで来たら、テストスイートがパスすることを確認しましょう。
$ bundle exec rspec spec/
6.3.5ユーザーを作成する
以上でUserモデルの基本部分が完了しましたので、今度は7.1でユーザー情報表示ページを作成するときに備えて、データベースに新規ユーザーを1人作成しましょう。この作業によって、これまでの節で行なってきた実装が動作することも実感できることでしょう。テストスイートがパスするだけでは味気ないので、実際に開発データベースにユーザーを登録することで喜びを感じていただければと思います。
ただしWebからのユーザー登録はまだできない (完成は第7章です) ので、Railsコンソールを使用して手動でユーザーを作成することにしましょう。6.1.3のときとは異なり、今回はサンドボックスで起動する必要はありません。データベースに実際にレコードを保存しなければ意味がないからです。
$ rails console
>> User.create(name: "Michael Hartl", email: "mhartl@example.com",
?> password: "foobar", password_confirmation: "foobar")
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",
created_at: "2013-03-11 20:45:19", updated_at: "2013-03-11 20:45:19",
password_digest: "$2a$10$kn4cQDJTzV76ZgDxOWk6Je9A0Ttn...">
実際にデータが登録されたことを確認するために、SQLite Database Browserを使用して開発データベース (db/development.sqlite3) の中にある行を見てみましょう (図6.6)。データモデルの属性に対応するカラムは図6.5で定義されていることを思い出してください。
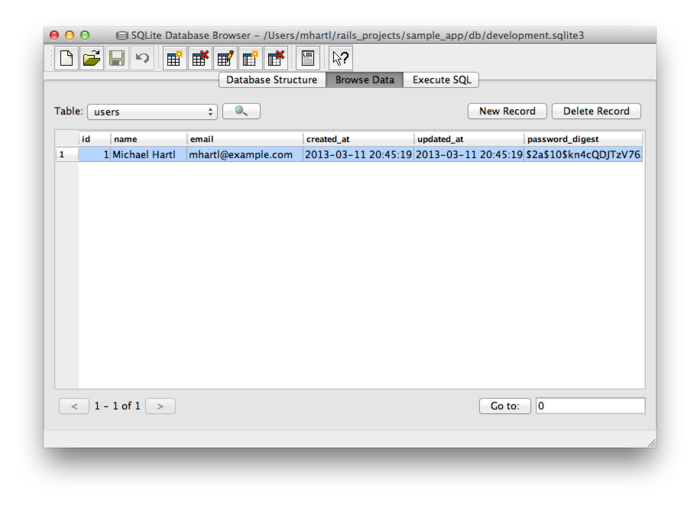
db/development.sqlite3に登録されたユーザーの行。(拡大){kind=link}
コンソールに戻ってpassword_digest属性を参照してみると、リスト6.29のhas_secure_passwordの効果を確認できます。
>> user = User.find_by(email: "mhartl@example.com")
>> user.password_digest
=> "$2a$10$kn4cQDJTzV76ZgDxOWk6Je9A0Ttn5sKNaGTEmT0jU7.n..."
上の文字列は、パスワード ("foobar") を暗号化したものであり、ユーザーオブジェクトを初期化するのに使用されました。また、最初に無効なパスワード、次に有効なパスワードを与えることでauthenticateの動作を確認することもできます。
>> user.authenticate("invalid")
=> false
>> user.authenticate("foobar")
=> #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com",
created_at: "2013-03-11 20:45:19", updated_at: "2013-03-11 20:45:19",
password_digest: "$2a$10$kn4cQDJTzV76ZgDxOWk6Je9A0Ttn...">
リスト6.28のテストの要求に従って、authenticateメソッドはパスワードが無効なときはfalseを返し、パスワードが有効なときはユーザー自身を返しています。
6.4最後に
この章では、まったく最初からUserモデルを作成し、それにname属性とemail属性を与え、さまざまなパスワード属性も与え、値を制限する多くの重要な検証も追加しました。さらに、与えられたパスワードをセキュアに認証できるようにしました。以前のバージョンのRailsであれば、このような実装を行うためのコードは現在の倍以上になっていたことでしょう。しかし今ではコンパクトな validatesメソッドとhas_secure_passwordメソッドのおかげで、ほんの数行のコードを書くだけで完全なUserモデルを作成できるようになりました。
次の第7章では、ユーザーを作成するためのユーザー登録フォームを作成し、各ユーザーの情報を表示するためのページも作成します。第8章では、6.3の認証システムを利用して、ユーザーが実際にWebサイトにサインインできるようにします。
Gitを使用している方は、しばらくコミットしていなかったのであれば、この時点でコミットしておくのがよいでしょう。
$ git add .
$ git commit -m "Make a basic User model (including secure passwords)"
次にmasterブランチにマージバックします。
$ git checkout master
$ git merge modeling-users
6.5演習
- リスト6.20の、メールアドレスを小文字に変換するコードに対するテストを、リスト6.30に示されているように作成してください。このテストでは、
reloadメソッドを使用してデータベースから値を再度読み込み、eqメソッドを使用して同値であるかどうかをテストしてください。before_saveの行をコメントアウトすることで、リスト6.30が正しい対象をテストしていることを確認してください。 before_saveコールバックをリスト6.31のように書いてもよいことを、テストスイートを実行して確認してください (訳注: この実装案を採用すると、前問で追加したテストが意味のないものになります。その理由についても考えてみてください)。- 6.2.4で説明したように、 リスト6.14のメールアドレスチェック用正規表現は、“foo@bar..com”のようにドットが連続した無効なメールアドレスを許容してしまいます。このメールアドレスをリスト6.13の無効なメールアドレスリストに追加し、これによってテストが失敗することを確認してください。次に、リスト6.32に示したもう少し複雑な正規表現を使用して、このテストがパスするようにしてください。
- Rails APIサイトの
ActiveRecord::Baseの項を読み通し、どんなことができるかを把握してください。 - Rails APIサイトで
validatesメソッドを調べ、どんなことができるか、どんなオプションがあるかを調べてください。 - Rubularで2〜3時間ほど遊んでみてください。
require 'spec_helper'
describe User do
.
.
.
describe "email address with mixed case" do
let(:mixed_case_email) { "Foo@ExAMPle.CoM" }
it "should be saved as all lower-case" do
@user.email = mixed_case_email
@user.save
expect(@user.reload.email).to eq mixed_case_email.downcase
end
end
.
.
.
end
before_saveコールバックの別の実装。app/models/user.rb class User < ActiveRecord::Base
has_secure_password
before_save { email.downcase! }
.
.
.
end
app/models/user.rb class User < ActiveRecord::Base
.
.
.
VALID_EMAIL_REGEX = /\A[\w+\-.]+@[a-z\d\-]+(\.[a-z]+)*\.[a-z]+\z/i
validates :email, presence: true, format: { with: VALID_EMAIL_REGEX },
uniqueness: { case_sensitive: false }
.
.
.
end
- この名前の由来は 'active record pattern です。Martin Fowler著「エンタープライズ アプリケーションアーキテクチャパターン 」で特定および命名されました。↑
- 「エスキューエル」と発音しますが、「スィークゥエル」もよく使われます。↑
- メールアドレスをユーザー名にしたことで、理屈の上では将来ユーザー同士で通信できるように拡張できる可能性が開かれます。↑
tオブジェクトが具体的に何をしているのかを正確に知る必要はありませんので、どうか心配しないでください。抽象化レイヤの素晴らしい点は、それが何であるかを知る必要がないという点です。安心してtオブジェクトに仕事を任せればよいのです。↑- 公式には「エスキューエライト (ess-cue-ell-ite)」と発音しますが、本来は誤りとされている「スィークゥエライト (sequel-ite)」もよく使われています。↑
"2013-03-11 00:57:46"というタイムスタンプが気になった方もいると思いますが、著者はこの箇所を真夜中過ぎに書いたわけではありません。実はこのタイムスタンプは協定世界時 (UTC) に合わせてあります。これはグリニッジ標準時 (GMT) と同様、標準時間として使用されます。「NIST時刻と周波数FAQ」によると、問: 協定世界時 (Coordinated Universal Time) の略称がCUTではなくUTCなのはなぜですか。答え: 協定世界時システムは、1970年に国際電気通信連合 (ITU) の技術専門家の国際諮問グループによって考案されました。このときITUは、混乱を最小限にとどめるために、略称を1つだけにしたいと考えました。このとき、英語式のCUTもフランス式のTUCも満場一致とならず、両者の妥協案としてUTCという略語が採用されました。↑user.updated_atの値に注目してください。上の脚注にも書いたとおり、このタイムスタンプはUTCベースです。↑- 例外と例外ハンドリングは、ある意味でRubyの高度なテーマです。本書では例外についてこれ以上言及しません。しかし例外が重要なものであることも確かなので、1.1.1で推薦したRuby本で例外について詳しく学ぶことをおすすめします↑
- 今後、コンソールコマンドの出力は、特に教育的効果が高いと思える場合 (ここでの
User.newの場合など) を除いて省略いたします。↑ - 表6.1の正規表現の説明における「文字」は、実は「小文字のみ」が対象になっていることに注意してください。ただし、正規表現の末尾に
iオプションを追加してあるので、大文字小文字が区別されずにマッチするようになっています。↑ - 著者同様このツールを便利だと思ってくださる方は、Michael Lovittの素晴らしい成果に報いるために、どうかRubularへの寄付をお願いいたします。↑
- 驚いたことに、公式標準によると
"Michael Hartl"@example.comのようなクォートとスペースを使用したメールアドレスも有効なのだそうです。まったく馬鹿げています。↑ - この節の冒頭で簡単に紹介したように、この目的に使用できる専用のテストデータベース
db/test.sqlite3があります。↑ - 技術的には、メールアドレスのうちドメイン名部分だけが (本当は) 大文字小文字を区別しません。foo@bar.comは、本来はFoo@bar.comとは別のアドレスです。ただし現実的には、about.comでも指摘されているように、メールアドレスの大文字小文字を区別することを前提にするのはまずい方法です。「メールアドレスの大文字小文字を区別すると、果てしない混乱と相互運用性の問題とひどい頭痛が発生する。メールアドレスの入力時に大文字小文字の区別を要求するのは賢い方法とは言えない。現実には、メールアドレスの大文字小文字の区別を強制するメールサービスやISPはめったに存在しない。メールアドレスのすべての文字を大文字にするなど、受信者のメールアドレスが誤って入力されていれば、メールは返送されるだけだ。」Riley Mosesによるご指摘に感謝いたします。↑
- もちろん、リスト6.2の
usersテーブル用のマイグレーションファイルを単に編集することも可能なのですが、その場合ロールバックが必要となり、マイグレーションが戻ってしまいます。データモデルの変更が必要になったらその都度マイグレーションを行うのがRails流です。↑ - 著者のシステム上のSQLiteとHeroku上のPostgreSQLで直接実験してみたところ、この手順は実際に必要であることがわかりました。↑
- http://railstutorial.jp/book?version=3.0 ↑
Railsチュートリアルは YassLab 社によって運営されています。
コンテンツを継続的に提供するため、書籍・動画・質問対応サービスなどもご検討していただけると嬉しいです。
研修支援や教材連携にも対応しています。note マガジンや YouTube チャンネルも始めたので、よければぜひ遊びに来てください!