Ruby on Rails チュートリアル









Ruby on Rails チュートリアル
プロダクト開発の0→1を学ぼう
第4版 目次
- 第1章ゼロからデプロイまで
- 第2章Toyアプリケーション
- 第3章ほぼ静的なページの作成
- 第4章Rails風味のRuby
- 第5章レイアウトを作成する
- 第6章ユーザーのモデルを作成する
- 第7章ユーザー登録
- 第8章基本的なログイン機構
- 第9章発展的なログイン機構
- 第10章ユーザーの更新・表示・削除
- 第11章アカウントの有効化
- 第12章パスワードの再設定
- 第13章ユーザーのマイクロポスト
- 第14章ユーザーをフォローする
第4章Rails風味のRuby
この章では、第3章で使った例を基に、Railsにおいて重要となるRubyのさまざまな要素について探っていくことにしましょう。Rubyは巨大な仕様を持つ言語ですが、幸い、Rails開発者にとって必要な知識は比較的少なくて済みます。また、一般のRuby入門書で扱っている内容とも多少異なっています。この章の目的は、「Rails風味のRuby」というものについての確固たる基盤を、皆さんのこれまでの言語経験に関わらず提供することです。この章には多くの話題が盛り込まれていますが、一度読んだだけで理解する必要はまったくありません。今後もこの章には頻繁に立ち戻って参照します。
4.1 動機
前章でお見せしたとおり、Rubyの基礎知識がまったくない状態であったにもかかわらずRailsアプリケーションの骨組みを作り上げ、さらにテストまで行うことができました。このときは、本書が提供するテストコードと、テストスイートがパスするまでエラーメッセージの修正を繰り返すという方法だけを頼りに作業を進めました。しかしこのような初歩的な作業をいつまでも続けるわけにはいきませんので、今の私たちのRubyに関する知識と経験の限界に真正面から挑み、これを乗り越えるためにこの章を割り当てることにします。
まずは3.2のときと同様にトピックブランチを作り、そこで変更をコミットしていきましょう。
$ git checkout -b rails-flavored-ruby
トピックブランチでコミットした変更は、4.5でマージすることにします。
4.1.1 組み込みヘルパー
前章の終わりでは、Railsのレイアウトを使ってビューでの重複を取り除き、ほぼ静的なページを少し更新しました (リスト 4.1)。これは、リスト 3.35と同じものです。
app/views/layouts/application.html.erb
<!DOCTYPE html>
<html>
<head>
<title><%= yield(:title) %> | Ruby on Rails Tutorial Sample App</title>
<%= csrf_meta_tags %>
<%= stylesheet_link_tag 'application', media: 'all',
'data-turbolinks-track': 'reload' %>
<%= javascript_include_tag 'application',
'data-turbolinks-track': 'reload' %>
</head>
<body>
<%= yield %>
</body>
</html>
リスト 4.1の次の行にご注目ください。
<%= stylesheet_link_tag 'application', media: 'all',
'data-turbolinks-track': 'reload' %>
ここではRailsの組み込み関数stylesheet_link_tag (詳細はRails API参照) を使って、application.cssをすべてのメディアタイプで使えるようにしています (メディアタイプにはコンピュータの画面や印刷画面なども含まれます)。Rails開発経験者にとってこの行は実にシンプルですが、しかしここには少なくとも混乱を生じる可能性のあるRubyの概念が4つあります。Railsの組み込み関数、カッコを使わないメソッド呼び出し、シンボル、そしてハッシュです。これらの概念も本章ですべて説明します。
4.1.2 カスタムヘルパー
Railsのビューでは膨大な数の組み込み関数が使えますが、それだけでなく、新しく作成することもできます。新しく作ったメソッドはカスタムヘルパー と呼ばれます。カスタムヘルパーの作成方法を学ぶため、まずはリスト 4.1のタイトル行に注目しましょう。
<%= yield(:title) %> | Ruby on Rails Tutorial Sample App
上の行は、ページタイトルの定義に依存しています。この定義は、次のようにビューでprovideが使われています。
<% provide(:title, "Home") %>
<h1>Sample App</h1>
<p>
This is the home page for the
<a href="https://railstutorial.jp/">Ruby on Rails Tutorial</a>
sample application.
</p>
このとき、もしタイトルをまったく与えていなければ、タイトルが空欄になってしまいます。これを防ぐには、すべてのページで使う基本タイトルを定め、特定のページでは異なるタイトルに変更できるようなオプションを与えるのが常套手段です。これは現在のレイアウトでも、ある点を除いて達成されています。もしビューの1つからprovide呼び出しを削除すると、そのページ固有のタイトルの代わりに次のタイトルが表示されます。
| Ruby on Rails Tutorial Sample App
基本タイトルとしてはこれで正しいのですが、先頭に余分な縦棒 | が残ってしまっています。
ページタイトルが正しく表示されない問題を解決するために、full_titleというヘルパーを作成することにします。full_titleヘルパーは、ページタイトルが定義されていない場合は基本タイトル「Ruby on Rails Tutorial Sample App」を返し、定義されている場合は基本タイトルに縦棒とページタイトルを追加して返します (リスト 4.2)1。
full_titleヘルパーを定義する app/helpers/application_helper.rb
module ApplicationHelper
# ページごとの完全なタイトルを返します。
def full_title(page_title = '')
base_title = "Ruby on Rails Tutorial Sample App"
if page_title.empty?
base_title
else
page_title + " | " + base_title
end
end
end
ヘルパーを作成したので、これを使ってレイアウトをシンプルにすることができます。
<title><%= yield(:title) %> | Ruby on Rails Tutorial Sample App</title>
つまり、上のコードが下のようになります。
<title><%= full_title(yield(:title)) %></title>
置き換えた結果をリスト 4.3に示します。
full_titleヘルパーを使ったWebサイトのレイアウト green app/views/layouts/application.html.erb
<!DOCTYPE html>
<html>
<head>
<title><%= full_title(yield(:title)) %></title>
<%= csrf_meta_tags %>
<%= stylesheet_link_tag 'application', media: 'all',
'data-turbolinks-track': 'reload' %>
<%= javascript_include_tag 'application',
'data-turbolinks-track': 'reload' %>
</head>
<body>
<%= yield %>
</body>
</html>
このヘルパーを定義することで、Homeページにこれまで表示されていた余分な「Home」という単語を表示せず、基本タイトルのみを正しく表示することもできるようになります。これを行うには、まずリスト 4.4に示すように以前のテストコードを更新し、"Home" という文字が表示されていないことを確認するテストを追加します。
test/controllers/static_pages_controller_test.rb
require 'test_helper'
class StaticPagesControllerTest < ActionDispatch::IntegrationTest
test "should get home" do
get static_pages_home_url
assert_response :success
assert_select "title", "Ruby on Rails Tutorial Sample App"
end
test "should get help" do
get static_pages_help_url
assert_response :success
assert_select "title", "Help | Ruby on Rails Tutorial Sample App"
end
test "should get about" do
get static_pages_about_url
assert_response :success
assert_select "title", "About | Ruby on Rails Tutorial Sample App"
end
end
ここでテストスイートを実行して、テストが失敗することを確認します。
$ rails test
3 tests, 6 assertions, 1 failures, 0 errors, 0 skips
テストがパスするためには、リスト 4.6のようにHomeページのビューからprovide の行を削除する必要があります。
app/views/static_pages/home.html.erb
<h1>Sample App</h1>
<p>
This is the home page for the
<a href="https://railstutorial.jp/">Ruby on Rails Tutorial</a>
sample application.
</p>
この時点で、テストはパスするはずです。
$ rails test
注意: これまではrails testを実行した結果の一部 (成功結果や失敗結果など) も載せていましたが、紙幅の関係から、今後は実行結果を省略します。
Rails開発経験者にとって、4.1.1で紹介したリスト 4.2のコードは、スタイルシートを読み込むのと大差ない単純なものですが、ここにもRubyの重要な概念が多数含まれています。具体的にはモジュール、メソッド定義、任意のメソッド引数、コメント、ローカル変数の割り当て、論理値 (boolean)、制御フロー、文字列の結合、そして戻り値です。これらの概念について、この章で理解していきましょう。
4.2 文字列とメソッド
Ruby を学ぶためのツールとして、主にRailsコンソールを使っていくことにします。これは2.3.3で登場した、Railsアプリケーションを対話的に操作するためのコマンドラインツールです。Railsコンソールはirb (IRB: Interactive RuBy) を拡張して作られているため、Rubyの機能をすべて使うことができます (4.4.4でも説明しますが、RailsコンソールからRails環境にアクセスすることもできます)。
クラウドIDEをご利用の場合は、オススメのirbの設定があります。シンプルなテキストエディタ「nano」を使って、まずはホームディレクトリに「.irbrc」ファイルを作ってみましょう2。
$ nano ~/.irbrc
次に、リスト 4.8のような設定を書きます。この設定によりirbのプロンプトが簡潔な表示に置き換えられ、irbの邪魔な自動インデント機能がオフになります。
~/.irbrc
IRB.conf[:PROMPT_MODE] = :SIMPLE
IRB.conf[:AUTO_INDENT_MODE] = false
最後に、Ctrl-Xと押してnanoエディタから離脱します。ファイルを保存するかどうか訊かれるので、yキーを押して~/.irbrcファイルを保存しましょう。
これで準備が整ったので、次のコマンドを実行して早速Railsコンソールを起動してみましょう。
$ rails console
Loading development environment
>>
デフォルトでは、コンソールはdevelopment (開発) 環境という、Railsによって定義された3種類の環境のうちの1つで起動します (他の2つはtest (テスト) 環境とproduction (本番) 環境です)。この区別は本章においてあまり重要ではありません。ただ、次章以降では重要になってくるので、7.1.1でこれらの環境について詳しく説明することにします。
Railsコンソールは素晴しい学習ツールであり、その中を自由に探索できます。コンソールの中で何をしようとも、何かを壊すことは (まず) ありえないので、ご安心ください。もしRailsコンソールが何かおかしな挙動になったら、Ctrl-Cを押してコンソールから強制的に抜け出すことができます。もしくは、Ctrl-Dを押して正常にコンソールを終了させることもできます (このようなトラブルシューティングは『コマンドライン編』の「トラブルから脱出する方法」でまとめています)。なお、一般的なターミナルと同じで、Ctrl-Pまたは上矢印キーで以前に実行したコマンドを再利用することができます。時間の節約になるので、ぜひ活用してみてください。
また、本章を進めるにあたり気になるコードがあれば、有用なリソースであるRuby API (英語) を参照しながら学習することをぜひオススメします 。Ruby APIには高濃縮の情報が詰まっています (少々濃厚すぎるとも言えます)。例えばRubyの文字列の詳細を知りたい場合は、Ruby APIエントリのStringクラスを参照すればよいのです。
訳注: 日本語ではRubyリファレンスマニュアル (通称: るりま)) やるりまサーチが大変便利です。
4.2.1 コメント
Rubyのコメントはナンバー記号# (「ハッシュマーク」や「オクトソープ」とも呼ばれます) から始まり、その行の終わりまでがコメントとして扱われます。Rubyはコメントの内容を実行することはありませんが、適切なコメントはそれを読む人間にとって (コードの作者にとっても) 非常に有用です。例えば次のコードの場合、
# ページごとの完全なタイトルを返します。
def full_title(page_title = '')
.
.
.
end
最初の行が、その後に定義されているメソッドの目的を説明しているコメントになります。
コメントをコンソール内で入力する人は普通いませんが、ここでは学習のためにあえて次のようにコメントを追加してみましょう。
$ rails console
>> 17 + 42 # 整数の足し算
=> 59
この章のコードを (ファイルに保存するのでなく) Railsコンソールに入力したりコピペしたりするときであれば、コメントを省略してもかまいません。コメントをRailsコンソールに入力しても、コメントは常に無視されるので問題ありません。
4.2.2 文字列
文字列 (string) は、Webアプリケーションにおいておそらく最も重要なデータ構造です。これは、Webページというものが究極的にはサーバーからブラウザに送信された文字列にすぎないためです。それでは、コンソールで文字列について調べてみましょう。
$ rails console
>> "" # 空の文字列
=> ""
>> "foo" # 空ではない文字列
=> "foo"
ここで入力したものは文字列リテラルと呼ばれ (面白いことにリテラル文字列とも呼ばれます)ダブルクォート " で囲むことで作成できます。このコンソールは、入力したそれぞれの行を評価した結果を表示しており、文字列リテラルの場合には文字列自身が表示されます。
+ 演算子を使って、文字列を結合することもできます。
>> "foo" + "bar" # 文字列の結合
=> "foobar"
評価の結果は、"foo" と "bar" を足した"foobar"になりました3。
文字列を組み立てる他の方法として式展開 (interpolation) というものがあり、#{}という特殊な構文を使います4。
>> first_name = "Michael" # 変数の代入
=> "Michael"
>> "#{first_name} Hartl" # 文字列の式展開
=> "Michael Hartl"
例えば"Michael"という値をfirst_name変数に代入 (assign) し、この変数を "#{first_name} Hartl" という形で文字列の中に埋め込むと、文字列の中でその変数が展開されるようになります。同様にして、苗字と名前の両方を変数に割り当ててみましょう。
>> first_name = "Michael"
=> "Michael"
>> last_name = "Hartl"
=> "Hartl"
>> first_name + " " + last_name # 苗字と名前の間に空白を入れた結合
=> "Michael Hartl"
>> "#{first_name} #{last_name}" # 式展開を使って結合 (上と全く同じ)
=> "Michael Hartl"
最後の2つの結果は、全く同じ結果 (「等価」と言います) になっていますね。なお、著者は後者の式展開の方が好みです。空白を" "のように直接加えるのはどうもぎこちなく思えるからです。
出力
文字列を出力したい (画面に表示したい) ときに 、Rubyのメソッドで最も一般に使われるのはputsです (putの三人称単数現在形ではなく「put string」の略なので、本来は「put ess」と発音しますが、最近は「puts」と発音されることも多くなってきました)。
>> puts "foo" # 文字列を出力する
foo
=> nil
putsメソッドでは副作用が重要な役割を果たします。どういうことかと言うと、puts "foo"は文字列「"foo"」を副作用としてスクリーンに表示しますが、戻り値には「文字どおりの無」であるnilを返します。nilは「何にもない」ことを表すRubyの特別な値です。なお、=> nil という結果は、簡素化のために今後省略することがあります。
上の例からも分かるように、putsを使って出力すると、改行文字である\nが自動的に出力の末尾に追加されます (これはターミナルのechoコマンドと同じ振る舞いになります)。printメソッドも同様の出力を行いますが、次のように、改行文字を追加しない点が異なります。
>> print "foo" # 文字列の画面出力 (putsと同じだが改行がない)
foo=> nil
上の例が示すように、fooが出力された後に改行が入らないため、そのまま => nil が続いてしまっています。
意図的に改行を追加したいときは、「バックスラッシュ (\) + n」( \n) という改行文字を使います。この改行文字とprintを組み合わせると、putsと同じ振る舞いを再現することができます。
>> print "foo\n" # puts "foo" と等価
foo
=> nil
シングルクォート内の文字列
これまでの例ではすべてダブルクォート文字列を使っていましたが、Rubyではシングルクォートもサポートしています。ほとんどの場合、ダブルクォートとシングルクォートのどちらを使っても実質的に同じです。
>> 'foo' # シングルクォートの文字列
=> "foo"
>> 'foo' + 'bar'
=> "foobar"
ただし、1つ重要な違いがあります。Rubyはシングルクォート文字列の中では式展開を行いません。
>> '#{foo} bar' # シングルクォート内の文字列では式展開ができない
=> "\#{foo} bar"
逆に言えば、ダブルクォート文字列を用いた文字列で#のような特殊な文字を使いたい場合は、この文字をバックスラッシュでエスケープ (escape) する必要があります。
ダブルクォート文字列でもシングルクォート文字列と同じことができ、ダブルクォート文字列では式展開もできるのであれば、シングルクォート文字列にはどのような使い道があるのでしょうか。シングルクォートは、入力した文字をエスケープせずに「そのまま」保持するときに便利です。例えば「バックスラッシュ」の文字は、改行文字 \nと同様に多くのシステム上で特殊な文字として扱われます。なお、シングルクォートで文字列を囲めば、簡単にバックスラッシュ文字のような特殊文字をそのまま変数に含めることができます。
>> '\n' # 'バックスラッシュ n' をそのまま扱う
=> "\\n"
前述の#{文字と同様、Rubyでバックスラッシュそのものをエスケープする場合は、バックスラッシュがもう1つ必要です。ダブルクォート文字列の中では、バックスラッシュ文字そのものは2つのバックスラッシュによって表されます。このような些細な例の場合はそれほど問題になりませんが、次のようにエスケープの必要な文字が大量にある場合には、シングルクォートは非常に便利です。
>> 'Newlines (\n) and tabs (\t) both use the backslash character \.'
=> "Newlines (\\n) and tabs (\\t) both use the backslash character \\."
最後にもう一度申し上げます。ほとんどの場合、シングルクォートとダブルクォートのどちらを使おうと大きな違いはありません。実際、一般のソースコードでは、明確な理由もなく両者が混用されているケースをよく見かけます。以上でRubyの文字列に関する説明は終わりです。あ、言い忘れていたことがありましたね。「Rubyの世界へようこそ!」
演習
city変数に適当な市区町村を、prefecture変数に適当な都道府県を代入してください。- 先ほど作った変数と式展開を使って、「東京都 新宿区」のような住所の文字列を作ってみましょう。出力には
putsを使ってください。 - 上記の文字列の間にある半角スペースをタブに置き換えてみてください。(ヒント: 改行文字と同じで、タブも特殊文字です)
- タブに置き換えた文字列を、ダブルクォートからシングルクォートに置き換えてみるとどうなるでしょうか?
4.2.3 オブジェクトとメッセージ受け渡し
Rubyでは、あらゆるものがオブジェクトです。文字列やnilですらオブジェクトです。このことの技術的な意味は4.4.2で説明しますが、オブジェクトに関する意味や定義は、本を読んだだけでは中々わかりません。様々なオブジェクトの例に触れることで、「オブジェクトとは何であるか」という直感を養う必要があります。
逆に、オブジェクトが何をするかを説明するのは簡単です。オブジェクトとは (いついかなる場合にも) メッセージに応答するものです。文字列のようなオブジェクトは、例えばlengthというメッセージに応答できますが、これは文字列の文字数を返します。
>> "foobar".length # 文字列に "length" というメッセージを送る
=> 6
オブジェクトに渡されるメッセージは、一般にはメソッドと呼ばれます。メソッドの実体は、そのオブジェクト内で定義されたメソッドです5。Rubyの文字列は、次のようにempty?メソッドにも応答することができます。
>> "foobar".empty?
=> false
>> "".empty?
=> true
empty?メソッドの末尾にある疑問符にご注目ください。Rubyでは、メソッドがtrueまたはfalseという論理値 (boolean) を返すことを、末尾の疑問符で示す慣習があります。 論理値は、特に処理の流れを変更するときに有用です。
>> s = "foobar"
>> if s.empty?
>> "The string is empty"
>> else
>> "The string is nonempty"
>> end
=> "The string is nonempty"
条件文を2つ以上含めたい場合は、elsif (else + if) という文を使います。
>> if s.nil?
>> "The variable is nil"
>> elsif s.empty?
>> "The string is empty"
>> elsif s.include?("foo")
>> "The string includes 'foo'"
>> end
=> "The string includes 'foo'"
なお、論理値はそれぞれ && (and) や || (or)、! (not) オペレーターで表すこともできます。
>> x = "foo"
=> "foo"
>> y = ""
=> ""
>> puts "Both strings are empty" if x.empty? && y.empty?
=> nil
>> puts "One of the strings is empty" if x.empty? || y.empty?
"One of the strings is empty"
=> nil
>> puts "x is not empty" if !x.empty?
"x is not empty"
=> nil
Rubyでは、あらゆるものがオブジェクトです。したがって、nilもオブジェクトであり、これも多くのメソッドに応答できます。ほぼあらゆるオブジェクトを文字列に変換するto_sメソッドを使って、nilがメソッドに応答する例をお目にかけましょう。
>> nil.to_s
=> ""
確かに空文字列が出力されました。今度はnilに対してメソッドをチェーン (chain) して渡せることを確認します。
>> nil.empty?
NoMethodError: undefined method `empty?' for nil:NilClass
>> nil.to_s.empty? # メソッドチェーンの例
=> true
このように、nilオブジェクト自身はempty?メソッドには応答しないにもかかわらず、nil.to_sとすると応答することがわかります。
皆さんのご推察どおり、実はnilかどうかを調べるメソッドもあります。
>> "foo".nil?
=> false
>> "".nil?
=> false
>> nil.nil?
=> true
次のコードは、
puts "x is not empty" if !x.empty?
ifキーワードの別の使い方を示しています。Rubyではこのように、後続するifでの条件式が真のときにだけ実行される式 (後続if) を書くことができ、コードが非常に簡潔になります。なお、unlessキーワードも同様に使えます。
>> string = "foobar"
>> puts "The string '#{string}' is nonempty." unless string.empty?
The string 'foobar' is nonempty.
=> nil
Rubyにおいてnilは特別なオブジェクトです。Rubyのオブジェクトのうち、オブジェクトそのものの論理値がfalseになるのは、false自身とnilの2つしかありません。なお、「!!」(「バンバン (bang bang)」と読みます) という演算子を使うと、そのオブジェクトを2回否定することになるので、どんなオブジェクトも強制的に論理値に変換できます。
>> !!nil
=> false
その他のあらゆるRubyのオブジェクトは、ゼロですらtrueです。
>> !!0
=> true
演習
- "racecar" の文字列の長さはいくつですか?
lengthメソッドを使って調べてみてください。 reverseメソッドを使って、"racecar"の文字列を逆から読むとどうなるか調べてみてください。- 変数
sに "racecar" を代入してください。その後、比較演算子 (==) を使って変数sとs.reverseの値が同じであるかどうか、調べてみてください。 - リスト 4.9を実行すると、どんな結果になるでしょうか? 変数
sに "onomatopoeia" という文字列を代入するとどうなるでしょうか? ヒント: 上矢印 (またはCtrl-Pコマンド) を使って以前に使ったコマンドを再利用すると一からコマンドを全部打ち込む必要がなくて便利ですよ。)
>> puts "It's a palindrome!" if s == s.reverse
4.2.4 メソッドの定義
Railsコンソールでも、リスト 3.8のhomeアクションや、リスト 4.2のfull_titleヘルパーと同じ方法でメソッドを定義することができます (メソッドの定義はファイルで行うのが普通なので、コンソールで行うのは少々面倒ですが、デモが目的であれば十分です)。例えば引数を1つ取り、引数が空かどうかに基づいたメッセージを返すstring_messageというメソッドを定義してみましょう。
>> def string_message(str = '')
>> if str.empty?
>> "It's an empty string!"
>> else
>> "The string is nonempty."
>> end
>> end
=> :string_message
>> puts string_message("foobar")
The string is nonempty.
>> puts string_message("")
It's an empty string!
>> puts string_message
It's an empty string!
最後の例を見ると分かるように、メソッドの引数を省略することも可能です (カッコですら省略可能です)。これは次のコードで
def string_message(str = '')
引数にデフォルト値を含めているからです (この例のデフォルト値は空の文字列です)。このように指定すると、str変数に引数を渡すことも渡さないこともできます。引数を渡さない場合は、指定のデフォルト値が自動的に使われます。
ここで、Rubyのメソッドには「暗黙の戻り値がある」ことにご注意ください。これは、メソッド内で最後に評価された式の値が自動的に返されることを意味します (訳注: メソッドで戻り値を明示的に指定しなかった場合の動作です)。この場合、引数のstrが空かどうかに応じて、2つのメッセージ文字列のうちのいずれかを返します。もちろん、Rubyでは戻り値を明示的に指定することもできます。次のメソッドは上のメソッドと同じ結果を返します。
>> def string_message(str = '')
>> return "It's an empty string!" if str.empty?
>> return "The string is nonempty."
>> end
上の説明で気付いた方もいると思いますが、2番目のreturnは実はなくてもかまいません。メソッド内の最後に置かれた式 (この場合は "The string is nonempty.") は、returnキーワードがなくても暗黙で値を返すためです。ここでは、両方にreturnを使う方が見た目の対称性が保たれるので好ましいと言えます。
メソッドで引数の変数名にどんな名前を使っても、メソッドの呼び出し側には何の影響も生じないという点にもご注目ください。つまり、最初の例のstrを別の変数名 (the_function_argumentなど) に変更しても、メソッドの呼び出し方は全く同じです。
>> def string_message(the_function_argument = '')
>> if the_function_argument.empty?
>> "It's an empty string!"
>> else
>> "The string is nonempty."
>> end
>> end
=> :string_message
>> puts string_message("")
It's an empty string!
>> puts string_message("foobar")
The string is nonempty.
演習
- リスト 4.10の
(コードを書き込む)の部分を適切なコードに置き換え、回文かどうかをチェックするメソッドを定義してみてください。ヒント: リスト 4.9の比較方法を参考にしてください。 - 上で定義したメソッドを使って “racecar” と “onomatopoeia” が回文かどうかを確かめてみてください。1つ目は回文である、2つ目は回文でない、という結果になれば成功です。
palindrome_tester("racecar")に対してnil?メソッドを呼び出し、戻り値がnilであるかどうかを確認してみてください (つまりnil?を呼び出した結果がtrueであることを確認してください)。このメソッドチェーンは、nil?メソッドがリスト 4.10の戻り値を受け取り、その結果を返しているという意味になります。
>> def palindrome_tester(s)
>> if (コードを書き込む)
>> puts "It's a palindrome!"
>> else
>> puts "It's not a palindrome."
>> end
>> end
4.2.5 titleヘルパー、再び
これでfull_titleヘルパー (リスト 4.2) のコードを理解するための準備が整いました6。コメントを使って、各行の振る舞いに注釈を加えてみました (リスト 4.11)。
title_helper. app/helpers/application_helper.rb
module ApplicationHelper
# ページごとの完全なタイトルを返します。 # コメント行
def full_title(page_title = '') # メソッド定義とオプション引数
base_title = "Ruby on Rails Tutorial Sample App" # 変数への代入
if page_title.empty? # 論理値テスト
base_title # 暗黙の戻り値
else
page_title + " | " + base_title # 文字列の結合
end
end
end
Webサイトのレイアウトで使うコンパクトなヘルパーメソッドでは、メソッド定義、変数割り当て、論理評価、制御フロー、文字列の式展開7など、Rubyの様々な要素が投入されています。最後に、module ApplicationHelperという要素について解説します。モジュールは、関連したメソッドをまとめる方法の1つで、includeメソッドを使ってモジュールを読み込むことができます (ミックスイン (mixed in) とも呼びます)。単なるRubyのコードを書くのであれば、モジュールを作成するたびに明示的に読み込んで使うのが普通ですが、Railsでは自動的にヘルパーモジュールを読み込んでくれるので、include行をわざわざ書く必要がありません。つまり、このfull_titleメソッドは自動的にすべてのビューで利用できるようになっている、ということです。
4.3 他のデータ構造
Webアプリケーションは突き詰めればただの文字列に過ぎませんが、実際にはこれらの文字列を作るために文字列以外のデータ構造も必要となります。この節では、Railsアプリケーションを書くために重要となる、いくつかのRubyのデータ構造について説明します。
4.3.1 配列と範囲演算子
配列 (array) は、特定の順序を持つ要素のリストです。Railsチュートリアルではこれまで配列について解説していませんでしたが、配列を理解することは、ハッシュ (4.3.3) やRailsのデータモデルを理解するための重要な基盤となります (データモデルとはhas_manyなどの関連付けのことであり、2.3.3や13.1.3で詳しく説明します)。
Rubyの文字列の理解にだいぶ時間を使ってしまいましたので、次に進むことにします。splitメソッドを使うと、文字列を自然に変換した配列を得ることができます。
>> "foo bar baz".split # 文字列を3つの要素を持つ配列に分割する
=> ["foo", "bar", "baz"]
この操作によって、3つの文字列からなる配列が得られます。splitで文字列を区切って配列にするときにはデフォルトで空白が使われますが、次のように他の文字を指定して区切ることもできます。
>> "fooxbarxbaz".split('x')
=> ["foo", "bar", "baz"]
多くのコンピュータ言語の慣習と同様、Rubyの配列でもゼロオリジンを採用しています。これは、配列の最初の要素のインデックスが0から始まり、2番目は1...と続くことを意味します。
>> a = [42, 8, 17]
=> [42, 8, 17]
>> a[0] # Rubyでは角カッコで配列にアクセスする
=> 42
>> a[1]
=> 8
>> a[2]
=> 17
>> a[-1] # 配列の添字はマイナスにもなれる!
=> 17
上で示したとおり、配列の要素にアクセスするには角カッコを使います。Rubyでは、角カッコ以外にも配列の要素にアクセスする方法が提供されています8。
>> a # 配列「a」の内容を確認する
=> [42, 8, 17]
>> a.first
=> 42
>> a.second
=> 8
>> a.last
=> 17
>> a.last == a[-1] # == を使って比較する
=> true
最後の行では、等しいことを確認する比較演算子==を使ってみました。この演算子や != (“等しくない”) などの演算子は、他の多くの言語と共通です。
>> x = a.length # 配列も文字列と同様lengthメソッドに応答する
=> 3
>> x == 3
=> true
>> x == 1
=> false
>> x != 1
=> true
>> x >= 1
=> true
>> x < 1
=> false
配列は、上記コードの最初の行のlengthメソッド以外にも、さまざまなメソッドに応答します。
>> a
=> [42, 8, 17]
>> a.empty?
=> false
>> a.include?(42)
=> true
>> a.sort
=> [8, 17, 42]
>> a.reverse
=> [17, 8, 42]
>> a.shuffle
=> [17, 42, 8]
>> a
=> [42, 8, 17]
上のどのメソッドを実行した場合にも、a自身は変更されていないという点にご注目ください。配列の内容を変更したい場合は、そのメソッドに対応する「破壊的」メソッドを使います。破壊的メソッドの名前には、元のメソッドの末尾に「!」を追加したものを使うのがRubyの慣習です。
>> a
=> [42, 8, 17]
>> a.sort!
=> [8, 17, 42]
>> a
=> [8, 17, 42]
また、pushメソッド (または同等の<<演算子) を使って配列に要素を追加することもできます。
>> a.push(6) # 6を配列に追加する
=> [42, 8, 17, 6]
>> a << 7 # 7を配列に追加する
=> [42, 8, 17, 6, 7]
>> a << "foo" << "bar" # 配列に連続して追加する
=> [42, 8, 17, 6, 7, "foo", "bar"]
最後の例では、要素の追加をチェーン (chain) できることを示しました。他の多くの言語の配列と異なり、Rubyでは異なる型が配列の中で共存できます (上の場合は整数と文字列)。
上では、文字列を配列に変換するのにsplitを使いました。joinメソッドはこれと逆の動作です。
>> a
=> [42, 8, 17, 6, 7, "foo", "bar"]
>> a.join # 単純に連結する
=> "4281767foobar"
>> a.join(', ') # カンマ+スペースを使って連結する
=> "42, 8, 17, 6, 7, foo, bar"
範囲 (range) は、配列と密接に関係しています。to_aメソッドを使って配列に変換すると理解しやすいと思います。
>> 0..9
=> 0..9
>> 0..9.to_a # おっと、9に対してto_aを呼んでしまっていますね
NoMethodError: undefined method `to_a' for 9:Integer
>> (0..9).to_a # 丸カッコを使い、範囲オブジェクトに対してto_aを呼びましょう
=> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
0..9 は範囲として有効ですが、上の2番目の表記ではメソッドを呼ぶ際にカッコを追加する必要があることを示しています。
範囲は、配列の要素を取り出すのに便利です。
>> a = %w[foo bar baz quux] # %wを使って文字列の配列に変換
=> ["foo", "bar", "baz", "quux"]
>> a[0..2]
=> ["foo", "bar", "baz"]
インデックスに-1という値を指定できるのは極めて便利です。-1を使うと、配列の長さを知らなくても配列の最後の要素を指定することができ、これにより配列を特定の開始位置の要素から最後の要素までを一度に選択することができます。
>> a = (0..9).to_a
=> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>> a[2..(a.length-1)] # 明示的に配列の長さを使って選択
=> [2, 3, 4, 5, 6, 7, 8, 9]
>> a[2..-1] # 添字に-1を使って選択
=> [2, 3, 4, 5, 6, 7, 8, 9]
次のように、文字列に対しても範囲オブジェクトが使えます。
>> ('a'..'e').to_a
=> ["a", "b", "c", "d", "e"]
演習
- 文字列「A man, a plan, a canal, Panama」を ", " で分割して配列にし、変数
aに代入してみてください。 - 今度は、変数
aの要素を連結した結果 (文字列) を、変数sに代入してみてください。 - 変数
sを半角スペースで分割した後、もう一度連結して文字列にしてください (ヒント: メソッドチェーンを使うと1行でもできます)。リスト 4.10で使った回文をチェックするメソッドを使って、(現状ではまだ) 変数sが回文ではないことを確認してください。downcaseメソッドを使って、s.downcaseは回文であることを確認してください。 aからzまでの範囲オブジェクトを作成し、7番目の要素を取り出してみてください。同様にして、後ろから7番目の要素を取り出してみてください。(ヒント: 範囲オブジェクトを配列に変換するのを忘れないでください)
4.3.2 ブロック
配列と範囲はいずれも、ブロックを伴うさまざまなメソッドに対して応答することができます。ブロックは、Rubyの極めて強力な機能であり、かつわかりにくい機能でもあります。
>> (1..5).each { |i| puts 2 * i }
2
4
6
8
10
=> 1..5
上のコードでは、範囲オブジェクトである(1..5)に対してeachメソッドを呼び出しています。メソッドに渡されている{ |i| puts 2 * i }が、ブロックと呼ばれる部分です。|i|では変数名が縦棒「|」に囲まれていますが、これはブロック変数に対して使うRubyの構文で、ブロックを操作するときに使う変数を指定します。この場合、範囲オブジェクトのeachメソッドは、iという1つのローカル変数を使ってブロックを操作できます。そして、範囲に含まれるそれぞれの値をこの変数に次々に代入してブロックを実行します。
ブロックであることを示すには波カッコ で囲みますが、次のようにdoとendで囲んで示すこともできます。
>> (1..5).each do |i|
?> puts 2 * i
>> end
2
4
6
8
10
=> 1..5
ブロックには複数の行を記述できます (実際ほとんどのブロックは複数行です)。RailsチュートリアルではRuby共通の慣習に従って、短い1行のブロックには波カッコを使い、長い1行や複数行のブロックにはdo..end記法を使っています。
>> (1..5).each do |number|
?> puts 2 * number
>> puts '--'
>> end
2
--
4
--
6
--
8
--
10
--
=> 1..5
今度はiの代わりにnumberを使っていることにご注目ください。この変数 (ブロック変数) の名前は固定されていません。
ブロックは見た目に反して奥が深く、ブロックを十分に理解するためには相当なプログラミング経験が必要です。そのためには、ブロックを含むコードをたくさん読みこなすことでブロックの本質を会得する以外に方法はありません9。幸いなことに、人間には個別の事例を一般化する能力というものがあります。ささやかですが参考のために、mapメソッドなどを使ったブロックの使用例をいくつか挙げてみます。
>> 3.times { puts "Betelgeuse!" } # 3.timesではブロックに変数を使っていない
"Betelgeuse!"
"Betelgeuse!"
"Betelgeuse!"
=> 3
>> (1..5).map { |i| i**2 } # 「**」記法は冪乗 (べき乗)
=> [1, 4, 9, 16, 25]
>> %w[a b c] # %w で文字列の配列を作成
=> ["a", "b", "c"]
>> %w[a b c].map { |char| char.upcase }
=> ["A", "B", "C"]
>> %w[A B C].map { |char| char.downcase }
=> ["a", "b", "c"]
上に示したように、mapメソッドは、渡されたブロックを配列や範囲オブジェクトの各要素に対して適用し、その結果を返します。また、後半の2つの例では、mapのブロック内で宣言した引数 (char) に対してメソッドを呼び出しています。こういったケースでは省略記法が一般的で、次のように書くこともできます (この記法を“symbol-to-proc”と呼びます)。
>> %w[A B C].map { |char| char.downcase }
=> ["a", "b", "c"]
>> %w[A B C].map(&:downcase)
=> ["a", "b", "c"]
(メソッド名にシンボルが使われているので奇妙に見えるかもしれません。これについては4.3.3で説明します)。1つ面白い話があります。これは実は元々Ruby on Rails独自の記法でした。しかし多くの人がこの記法を好むようになったので、今ではRubyのコア機能として導入されています。
最後のブロックの例として、単体テストにも目を向けてみましょう (リスト 4.4)。
test "should get home" do
get static_pages_home_url
assert_response :success
assert_select "title", "Ruby on Rails Tutorial Sample App"
end
ここでは動作をすみずみまで理解する必要はありません (実際、筆者もこのコードをひと目で完璧に把握できるなどとは言いません)。ここで重要なのは、テストコードにdoというキーワードがあることに気付き、そこからテストの本体が「そもそもブロックでできている」ことに気付くことです。すなわち、このtestメソッドは文字列 (説明文) とブロックを引数にとり、テストが実行されるときにブロック内の文が実行される、ということが理解できます。
ところで、1.5.4でランダムなサブドメインを生成するために次のRubyコードを紹介しましたが、このコードを理解するための準備が整ったので、今こそ読み解いてみましょう。10
('a'..'z').to_a.shuffle[0..7].join
順を追ってこのコードを組み立ててみると、動作がよくわかります。
>> ('a'..'z').to_a # 英小文字を列挙した配列を作る
=> ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o",
"p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"]
>> ('a'..'z').to_a.shuffle # シャッフルする
=> ["c", "g", "l", "k", "h", "z", "s", "i", "n", "d", "y", "u", "t", "j", "q",
"b", "r", "o", "f", "e", "w", "v", "m", "a", "x", "p"]
>> ('a'..'z').to_a.shuffle[0..7] # 配列の冒頭8つの要素を取り出す
=> ["f", "w", "i", "a", "h", "p", "c", "x"]
>> ('a'..'z').to_a.shuffle[0..7].join # 取り出した要素を結合して1つの文字列にする
=> "mznpybuj"
演習
- 範囲オブジェクト
0..16を使って、各要素の2乗を出力してください。 yeller(大声で叫ぶ) というメソッドを定義してください。このメソッドは、文字列の要素で構成された配列を受け取り、各要素を連結した後、大文字にして結果を返します。例えばyeller(['o', 'l', 'd'])と実行したとき、"OLD"という結果が返ってくれば成功です。ヒント:mapとupcaseとjoinメソッドを使ってみましょう。random_subdomainというメソッドを定義してください。このメソッドはランダムな8文字を生成し、文字列として返します。ヒント: サブドメインを作るときに使ったRubyコードをメソッド化したものです。- リスト 4.12の「?」の部分を、それぞれ適切なメソッドに置き換えてみてください。ヒント:
split、shuffle、joinメソッドを組み合わせると、メソッドに渡された文字列 (引数) をシャッフルさせることができます。
>> def string_shuffle(s)
>> s.?('').?.?
>> end
>> string_shuffle("foobar")
=> "oobfra"
4.3.3 ハッシュとシンボル
ハッシュは本質的には配列と同じですが、インデックスとして整数値以外のものも使える点が配列と異なります (この理由から、Perlなどのいくつかの言語ではハッシュを連想配列と呼ぶこともあります)。ハッシュのインデックス (キーと呼ぶのが普通です) は、通常何らかのオブジェクトです。例えば、次のように文字列をキーとして使えます。
>> user = {} # {}は空のハッシュ
=> {}
>> user["first_name"] = "Michael" # キーが "first_name" で値が "Michael"
=> "Michael"
>> user["last_name"] = "Hartl" # キーが "last_name" で値が "Hartl"
=> "Hartl"
>> user["first_name"] # 要素へのアクセスは配列の場合と似ている
=> "Michael"
>> user # ハッシュのリテラル表記
=> {"last_name"=>"Hartl", "first_name"=>"Michael"}
ハッシュは、キーと値のペアを波カッコで囲んで表記します。キーと値のペアを持たない波カッコの組 ({}) は空のハッシュです。ここで重要なのは、ハッシュの波カッコは、ブロックの波カッコとはまったく別物であるという点です (これは確かに紛らわしい点です) 。ハッシュは配列と似ていますが、1つの重要な違いとして、ハッシュでは要素の「並び順」が保証されないという点があります11。もし要素の順序が重要である場合は、配列を使う必要があります。
ハッシュの1要素を角カッコを使って定義する代わりに、次のようにキーと値をハッシュロケットと呼ばれる=> によってリテラル表現するほうが簡単です。
>> user = { "first_name" => "Michael", "last_name" => "Hartl" }
=> {"last_name"=>"Hartl", "first_name"=>"Michael"}
ここではRubyにおける慣習として、ハッシュの最初と最後に空白を追加しています。この空白はあってもなくてもよく、コンソールでは無視されます (なぜスペースを置くようになったのかはわかりません。おそらく初期の有力な Rubyプログラマが好んだ結果、慣習となったのでしょう)。
ここまではハッシュのキーとして文字列を使っていましたが、Railsでは文字列よりもシンボルを使う方が普通です。シンボルは文字列と似ていますが、クォートで囲む代わりにコロンが前に置かれている点が異なります。例えば:nameはシンボルです。もちろん、余計なことを一切考えずに、シンボルを単なる文字列とみなしても構いません12。
>> "name".split('')
=> ["n", "a", "m", "e"]
>> :name.split('')
NoMethodError: undefined method `split' for :name:Symbol
>> "foobar".reverse
=> "raboof"
>> :foobar.reverse
NoMethodError: undefined method `reverse' for :foobar:Symbol
シンボルは、Ruby以外ではごく一部の言語にしか採用されていない特殊なデータ形式です。最初は奇妙に思うかもしれませんが、Railsではシンボルをふんだんに使っているので、すぐに慣れるでしょう。ただし文字列と違って、全ての文字が使えるわけではないことに注意してください
>> :foo-bar
NameError: undefined local variable or method `bar' for main:Object
>> :2foo
SyntaxError
とはいえ、一般的なアルファベットなどを使っている限りにおいては、シンボルで困ることはないでしょう。
ハッシュのキーとしてシンボルを採用する場合、user のハッシュは次のように定義できます。
>> user = { :name => "Michael Hartl", :email => "michael@example.com" }
=> {:name=>"Michael Hartl", :email=>"michael@example.com"}
>> user[:name] # :name に対応する値にアクセスする
=> "Michael Hartl"
>> user[:password] # 未定義のキーに対応する値にアクセスする
=> nil
最後の例を見ると、未定義のハッシュ値は単純にnilであることがわかります。
ハッシュではシンボルをキーとして使うことが一般的なので、Ruby 1.9からこのような特殊な場合のための新しい記法がサポートされました。
>> h1 = { :name => "Michael Hartl", :email => "michael@example.com" }
=> {:name=>"Michael Hartl", :email=>"michael@example.com"}
>> h2 = { name: "Michael Hartl", email: "michael@example.com" }
=> {:name=>"Michael Hartl", :email=>"michael@example.com"}
>> h1 == h2
=> true
2つ目の記法は、シンボルとハッシュロケットの組み合わせを、次のようにキーの名前の (前ではなく) 後にコロンを置き、その後に値が続くように置き換えたものです。
{ name: "Michael Hartl", email: "michael@example.com" }
この構成は、JavaScriptなど他の言語のハッシュ記法により近いものになっており、Railsコミュニティでも人気が高まっています。どちらの記法もよく使われているので、両方の見分けがつくことが重要です。ただ最初は少し見分けづらいのも事実です。例えば:nameはシンボルとして独立していますが、引数を伴わないname:では意味が成り立ちません。次のコードの:name =>とname:は、ハッシュとしてのデータ構造は全く同じです。つまり、
{ :name => "Michael Hartl" }
上のコードと、
{ name: "Michael Hartl" }
というコードは等価になります (一般的には省略記法が好まれますが、明示的に接頭にコロンをつけてシンボル (:name) であることを強調するという考え方もあります)。
リスト 4.13に示したように、ハッシュの値にはほぼ何でも使うことができ、他のハッシュを使うことすらできます。
>> params = {} # 'params' というハッシュを定義する ('parameters' の略)。
=> {}
>> params[:user] = { name: "Michael Hartl", email: "mhartl@example.com" }
=> {:name=>"Michael Hartl", :email=>"mhartl@example.com"}
>> params
=> {:user=>{:name=>"Michael Hartl", :email=>"mhartl@example.com"}}
>> params[:user][:email]
=> "mhartl@example.com"
Railsでは、このようなハッシュのハッシュ (またはネストされたハッシュ) が大量に使われています。実際の使用例は7.3で説明します。
配列や範囲オブジェクトと同様、ハッシュもeachメソッドに応答します。例えば、:successと:dangerという2つの状態を持つ flash という名前のハッシュについて考えてみましょう。
>> flash = { success: "It worked!", danger: "It failed." }
=> {:success=>"It worked!", :danger=>"It failed."}
>> flash.each do |key, value|
?> puts "Key #{key.inspect} has value #{value.inspect}"
>> end
Key :success has value "It worked!"
Key :danger has value "It failed."
ここで、配列のeachメソッドでは、ブロックの変数は1つだけですが、ハッシュのeachメソッドでは、ブロックの変数はキーと値の2つになっていることに注意してください。したがって、 ハッシュに対してeachメソッドを実行すると、ハッシュの1つの「キーと値のペア」ごとに処理を繰り返します。
最後の例として、便利なinspectメソッドを紹介します。これは要求されたオブジェクトを表現する文字列を返します。
>> puts (1..5).to_a # 配列を文字列として出力
1
2
3
4
5
>> puts (1..5).to_a.inspect # 配列のリテラルを出力
[1, 2, 3, 4, 5]
>> puts :name, :name.inspect
name
:name
>> puts "It worked!", "It worked!".inspect
It worked!
"It worked!"
ところで、オブジェクトを表示するためにinspectを使うことは非常によくあることなので、 pメソッドというショートカットがあります13。
>> p :name # 'puts :name.inspect' と同じ
:name
演習
- キーが
'one'、'two'、'three'となっていて、それぞれの値が'uno'、'dos'、'tres'となっているハッシュを作ってみてください。その後、ハッシュの各要素をみて、それぞれのキーと値を"'#{key}'はスペイン語で'#{value}'"といった形で出力してみてください。 person1、person2、person3という3つのハッシュを作成し、それぞれのハッシュに:firstと:lastキーを追加し、適当な値 (名前など) を入力してください。その後、次のようなparamsというハッシュのハッシュを作ってみてください。1.) キーparams[:father]の値にperson1を代入、2). キーparams[:mother]の値にperson2を代入、3). キーparams[:child]の値にperson3を代入。最後に、ハッシュのハッシュを調べていき、正しい値になっているか確かめてみてください。(例えばparams[:father][:first]がperson1[:first]と一致しているか確かめてみてください)userというハッシュを定義してみてください。このハッシュは3つのキー:name、:email、:password_digestを持っていて、それぞれの値にあなたの名前、あなたのメールアドレス、そして16文字からなるランダムな文字列が代入されています。- Ruby API (訳注: もしくはるりまサーチ) を使って、Hashクラスの
mergeメソッドについて調べてみてください。次のコードを実行せずに、どのような結果が返ってくるか推測できますか? 推測できたら、実際にコードを実行して推測があっていたか確認してみましょう。{ "a" => 100, "b" => 200 }.merge({ "b" => 300 })
4.3.4 CSS、再び
それでは、もう一度リスト 4.1に戻り、レイアウトに CSS (cascading style sheet) を追加する次の行を見てみましょう。
<%= stylesheet_link_tag 'application', media: 'all',
'data-turbolinks-track': 'reload' %>
今なら、このコードを理解できるようになったはずです。4.1でも簡単に説明した通り、Railsではスタイルシートを追加するための特別なメソッドを使っています。
stylesheet_link_tag 'application', media: 'all',
'data-turbolinks-track': 'reload'
上のコードでは、このメソッドを呼んでいます。しかし、ここで不思議な点がいくつもあります。第一に、丸カッコがありません。実は、Ruby では丸カッコは使用してもしなくても構いません。次の2つの行は等価です。
# メソッド呼び出しの丸カッコは省略可能。
stylesheet_link_tag('application', media: 'all',
'data-turbolinks-track': 'reload')
stylesheet_link_tag 'application', media: 'all',
'data-turbolinks-track': 'reload'
次に、media引数はハッシュのようですが、波カッコがない点が不思議です。実は、ハッシュがメソッド呼び出しの最後の引数である場合は、波カッコを省略できます。次の2つの行は等価です。
# 最後の引数がハッシュの場合、波カッコは省略可能。
stylesheet_link_tag 'application', { media: 'all',
'data-turbolinks-track': 'reload' }
stylesheet_link_tag 'application', media: 'all',
'data-turbolinks-track': 'reload'
最後に、Rubyが次のようなコードを正常に実行できているのが不思議です。
stylesheet_link_tag 'application', media: 'all',
'data-turbolinks-track': 'reload'
上のコードには途中に改行が含まれているにもかかわらずです。実は、Rubyは改行と空白を区別していません14。行を分割した理由は、1行を80字以内に収めてソースコードを読みやすくするためです15。
したがって、
stylesheet_link_tag 'application', media: 'all',
'data-turbolinks-track': 'reload'
上のコードではstylesheet_link_tagメソッドを2つの引数で呼んでいます。最初の引数である文字列は、スタイルシートへのパスを示しています。次の引数であるハッシュには2つの要素があり、最初の要素はメディアタイプを示し、次の要素はRails 4.0で追加されたturbolinksという機能をオンにしています。この結果、<%= %> で囲まれているコードを実行した結果がERbのテンプレートに挿入されるようになります。ブラウザ上でこのページのソースを表示すると、必要なスタイルシートが含まれていることを確認できます (リスト 4.14)。(CSSファイル名の後に、?body=1のような行が余分に表示されていることがあります。これらはRailsによって挿入されているもので、サーバー上で変更があった場合にブラウザがCSSを再読み込みするのに使います。)
<link data-turbolinks-track="true" href="/assets/application.css"
media="all" rel="stylesheet" />
4.4 Rubyにおけるクラス
Rubyではあらゆるものがオブジェクトであるということは既に説明しましたが、この節では実際にオブジェクトをいくつか定義してみましょう。Rubyは、多くのオブジェクト指向言語と同様、メソッドをまとめるのにクラスを使っています。これらのクラスからインスタンスが生成されることでオブジェクトが作成されます。オブジェクト指向プログラミングの経験がない方にとっては何のことだかわからないと思いますので、いくつかの具体例を示すことにします。
4.4.1 コンストラクタ
実は、これまで示した多くの例の中でも、クラスを使ってオブジェクトのインスタンスを作成してきたのですが、オブジェクトを作成するところを明示的に説明していませんでした。例えばダブルクォートを使って文字列のインスタンスを作成しましたが、これは文字列のオブジェクトを暗黙で作成するリテラルコンストラクタです。
>> s = "foobar" # ダブルクォートは実は文字列のコンストラクタ
=> "foobar"
>> s.class
=> String
上のコードでは、文字列がclassメソッドに応答しており、その文字列が所属するクラスを単に返していることがわかります。
暗黙のリテラルコンストラクタを使う代わりに、明示的に同等の名前付きコンストラクタを使うことができます。名前付きコンストラクタは、クラス名に対してnewメソッドを呼び出します16。
>> s = String.new("foobar") # 文字列の名前付きコンストラクタ
=> "foobar"
>> s.class
=> String
>> s == "foobar"
=> true
この動作はリテラルコンストラクタと等価ですが、動作の内容が明確に示されています。
配列でも、文字列と同様にインスタンスを生成できます。
>> a = Array.new([1, 3, 2])
=> [1, 3, 2]
ただし、ハッシュの場合は若干異なります。配列のコンストラクタであるArray.new は配列の初期値を引数に取りますが、 Hash.new はハッシュのデフォルト 値を引数に取ります。これは、キーが存在しない場合のデフォルト値です。
>> h = Hash.new
=> {}
>> h[:foo] # 存在しないキー (:foo) の値にアクセスしてみる
=> nil
>> h = Hash.new(0) # 存在しないキーのデフォルト値をnilから0にする
=> {}
>> h[:foo]
=> 0
メソッドがクラス自身 (この場合はnew) に対して呼び出されるとき、このメソッドをクラスメソッドと呼びます。クラスのnewメソッドを呼び出した結果は、そのクラスのオブジェクトであり、これはクラスのインスタンスとも呼ばれます。lengthのように、インスタンスに対して呼び出すメソッドはインスタンスメソッドと呼ばれます。
演習
- 1から10の範囲オブジェクトを生成するリテラルコンストラクタは何でしたか? (復習です)
- 今度は
Rangeクラスとnewメソッドを使って、1から10の範囲オブジェクトを作ってみてください。ヒント:newメソッドに2つの引数を渡す必要があります - 比較演算子
==を使って、上記2つの課題で作ったそれぞれのオブジェクトが同じであることを確認してみてください。
4.4.2 クラス継承
クラスについて学ぶとき、superclassメソッドを使ってクラス階層を調べてみるとよくわかります。
>> s = String.new("foobar")
=> "foobar"
>> s.class # 変数sのクラスを調べる
=> String
>> s.class.superclass # Stringクラスの親クラスを調べる
=> Object
>> s.class.superclass.superclass # Ruby 1.9からBasicObjectが導入
=> BasicObject
>> s.class.superclass.superclass.superclass
=> nil
継承階層を図 4.1に示します。ここでは、StringクラスのスーパークラスはObjectクラスで、ObjectクラスのスーパークラスはBasicObjectクラスですが、 BasicObjectクラスはスーパークラスを持たないことがわかります。この図式は、すべての Ruby のオブジェクトにおいて成り立ちます。クラス階層をたどっていくと、 Rubyにおけるすべてのクラスは最終的にスーパークラスを持たないBasicObjectクラスを継承しています。これが、"Rubyではあらゆるものがオブジェクトである" ということの技術的な意味です。
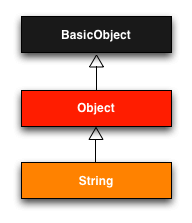
Stringクラスの継承階層
クラスについての理解を深めるには、自分でクラスを作成してみるのが一番です。そこで、Wordクラスを作成し、その中に、ある単語を前からと後ろからのどちらから読んでも同じ (つまり回文になっている) ならばtrueを返すpalindrome?メソッドを作成してみましょう。
>> class Word
>> def palindrome?(string)
>> string == string.reverse
>> end
>> end
=> :palindrome?
このクラスとメソッドは次のように使うことができます。
>> w = Word.new # Wordオブジェクトを作成する
=> #<Word:0x22d0b20>
>> w.palindrome?("foobar")
=> false
>> w.palindrome?("level")
=> true
もし上の例が少し不自然に思えるならば、勘が鋭いといえます。というのも、これはわざと不自然に書いたからです。文字列を引数に取るメソッドを作るためだけに、わざわざ新しいクラスを作るのは変です。単語は文字列なので、リスト 4.15のようにWordクラスは Stringクラスを継承するのが自然です (次のリストを入力する前に、古いWordクラスの定義を消去するために、Railsコンソールをいったん終了してください)。
Wordクラスを定義する。
>> class Word < String # WordクラスはStringクラスを継承する
>> # 文字列が回文であればtrueを返す
>> def palindrome?
>> self == self.reverse # selfは文字列自身を表します
>> end
>> end
=> :palindrome?
3.2でも簡単に説明しましたが、上のコードは継承のためのRubyの Word < String 記法です。こうすることで、新しいpalindrome?メソッドだけではなく、Stringクラスが扱えるすべてのメソッドがWordクラスでも使えるようになります。
>> s = Word.new("level") # 新しいWordを作成し、"level" で初期化する
=> "level"
>> s.palindrome? # Wordが回文かどうかを調べるメソッド
=> true
>> s.length # WordはStringで扱える全てのメソッドを継承している
=> 5
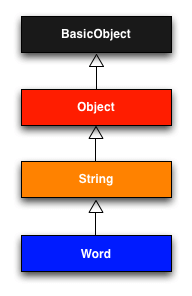
WordクラスはStringクラスを継承しているので、コンソールを使ってクラス階層を明示的に確認できます。
>> s.class
=> Word
>> s.class.superclass
=> String
>> s.class.superclass.superclass
=> Object
図 4.2にこのクラス階層を示します。
リスト 4.15では、単語の文字を逆順にしたものが元の単語と同じであるかどうかのチェックを、Wordクラスの中から自分自身が持つ単語にアクセスすることで行なっていることにご注目ください。Rubyでは、selfキーワードを使ってこれを指定することができます。Wordクラスの中では、selfはオブジェクト自身を指します。これはつまり、次のコードを使って、
self == self.reverse
単語が回文であるかどうかを確認できるということです17。なお、Stringクラスの内部では、メソッドや属性を呼び出すときのself.も省略可能です。
self == reverse
といった省略記法でも、うまく動きます。
4.4.3 組み込みクラスの変更
継承は強力な概念ですが、もし仮に継承を使わずにpalindrome?メソッドをStringクラス自身に追加して (つまりStringクラスを拡張して)、より自然な方法で使えるとしたら、わざわざWordクラスを作らなくてもpalindrome?をリテラル文字列に対して直接実行できるようになるはずです。そんなことが可能なのでしょうか (なお、現在のコードはそのようになっていないため、次のようにエラーになります)。
>> "level".palindrome?
NoMethodError: undefined method `palindrome?' for "level":String
驚いたことに、Rubyでは組み込みの基本クラスの拡張が可能なのです。Ruby のクラスはオープンで変更可能であり、クラス設計者でない開発者でもこれらのクラスにメソッドを自由に追加することが許されています。
>> class String
>> # 文字列が回文であればtrueを返す
>> def palindrome?
>> self == self.reverse
>> end
>> end
=> :String
>> "deified".palindrome?
=> true
(Rubyで組み込みクラスにメソッドを追加できるということは実にクールですが、"deified" (=神格化された) という単語が回文になっていることも、それに劣らずクールではないでしょうか。)
組み込みクラスの変更はきわめて強力なテクニックですが、大いなる力には大いなる責任が伴います (訳注: 「スパイダーマン」の名台詞)。このため、真に正当な理由がない限り、組み込みクラスにメソッドを追加することは無作法であると考えられています。Railsの場合、組み込みクラスの変更を正当化できる理由がいくつもあります。例えば Web アプリケーションでは、変数が絶対に空白にならないようにしたくなることがよくあります (ユーザー名などはスペースやその他の空白文字になって欲しくないものです) ので、Railsはblank?メソッドをRuby に追加しています。Railsの拡張は自動的にRailsコンソールにも取り込まれるので、次のようにコンソールで拡張の結果を確認できます (注意: 次のコードは純粋な irb では動作しません)。
>> "".blank?
=> true
>> " ".empty?
=> false
>> " ".blank?
=> true
>> nil.blank?
=> true
スペースが集まってできた文字列は空 (empty) とは認識されませんが、空白 (blank) であると認識されていることがわかります。ここで、nilは空白と認識されることに注意してください。nilは文字列ではないので、Railsが実はblank?メソッドをStringクラスではなく、そのさらに上の基底クラスに追加していることが推測できます。その基底クラスとは、(この章の最初で説明した) Object自身です。RailsによってRubyの組み込みクラスに追加が行われている例については、9.1で説明します。
演習
palindrome?メソッドを使って、“racecar”が回文であり、“onomatopoeia”が回文でないことを確認してみてください。南インドの言葉「Malayalam」は回文でしょうか? ヒント:downcaseメソッドで小文字にすることを忘れないで。- リスト 4.16を参考に、
Stringクラスにshuffleメソッドを追加してみてください。ヒント: リスト 4.12も参考になります。 - リスト 4.16のコードにおいて、
self.を削除してもうまく動くことを確認してください。
Stringクラスにshuffleメソッドを定義する (「?」を適切なメソッドを置き換えてください)
>> class String
>> def shuffle
>> self.?('').?.?
>> end
>> end
>> "foobar".shuffle
=> "borafo"
4.4.4 コントローラクラス
これまでクラスや継承について説明してきましたが、これらの話は前の章にもあったような気がします。それもそのはずで、StaticPagesコントローラで継承やクラスについて触れたことがありました (リスト 3.20)。
class StaticPagesController < ApplicationController
def home
end
def help
end
def about
end
end
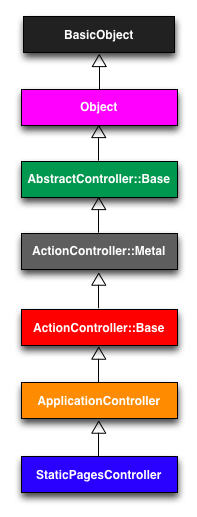
ここまでの説明を経て、ついにRailsのコードが説明できるようになります。今回はStaticPagesControllerはApplicationControllerを継承して定義されるhomeやhelp、aboutアクションを見ていきます。RailsコンソールはセッションごとにローカルのRails環境を読み込むので、コンソール内で明示的にコントローラを作成したり、そのクラス階層を調べたりすることができます。この仕組みを使って、早速Railsのコードを調べてみましょう18。
>> controller = StaticPagesController.new
=> #<StaticPagesController:0x22855d0>
>> controller.class
=> StaticPagesController
>> controller.class.superclass
=> ApplicationController
>> controller.class.superclass.superclass
=> ActionController::Base
>> controller.class.superclass.superclass.superclass
=> ActionController::Metal
>> controller.class.superclass.superclass.superclass.superclass
=> AbstractController::Base
>> controller.class.superclass.superclass.superclass.superclass.superclass
=> Object
継承の関係を図 4.3に示します。
Railsコンソールでは、その中からコントローラのアクション (実はメソッド) を呼ぶこともできます。
>> controller.home
=> nil
ここでは、homeアクションの中身は空なのでnilが返されます。
ここで重要な点があります。Railsのアクションには戻り値がありません。少なくとも、返される値は重要ではありません。第3章で示したとおり、home アクションはWebページを表示するためのものであり、値を返すためのものではありませんでした。しかも、第3章では一度もStaticPagesController.newを実行しませんでした。どうしてこれでうまくいっているのでしょうか。
実は、Railsは確かにRubyで書かれていますが、既にRubyとは別物なのです。Railsのクラスは、普通のRubyオブジェクトと同様に振る舞うものもありますが、多くのクラスにはRailsの魔法の粉が振りかけられています。Railsは独特であり、Rubyとは切り離して学習する必要があります。
4.4.5 ユーザークラス
最後に完全なクラスを作成して、この章を終わりにしましょう。そこで、第6章で使う User クラスを最初から作成することにします。
これまではコンソール上でクラスを定義しましたが、このような面倒な作業はもう行いたくありません。これからは、アプリケーションのルートディレクトリにexample_user.rbファイルを作成し、そこにリスト 4.17のように書くことにします。
example_user.rb
class User
attr_accessor :name, :email
def initialize(attributes = {})
@name = attributes[:name]
@email = attributes[:email]
end
def formatted_email
"#{@name} <#{@email}>"
end
end
上のコードはこれまでよりもやや複雑になっていますので、順に見ていくことにします。まず次の行は、
attr_accessor :name, :email
ユーザー名とメールアドレス (属性: attribute) に対応するアクセサー (accessor) をそれぞれ作成します。アクセサーを作成すると、そのデータを取り出すメソッド (getter) と、データに代入するメソッド (setter) をそれぞれ定義してくれます。具体的には、この行を実行したことにより、インスタンス変数@nameとインスタンス変数@emailにアクセスするためのメソッドが用意されます。2.2.2でも軽く触れましたが、Railsでは、インスタンス変数をコントローラ内で宣言するだけでビューで使えるようになる、といった点に主な利用価値があります。ただ一般的には、そのクラス内であればどこからでもアクセスできる変数として使われます (これについては後で詳しく説明します)。そしてインスタンス変数は常に@記号で始まり、まだ定義されていなければ値がnilになります。
次の行にあるinitializeは、Rubyの特殊なメソッドです。これは User.newを実行すると自動的に呼び出されるメソッドです。この場合のinitializeメソッドは、次のようにattributesという引数を1つ取ります。
def initialize(attributes = {})
@name = attributes[:name]
@email = attributes[:email]
end
上のコードで、attributes変数は空のハッシュをデフォルトの値として持つため、名前やメールアドレスのないユーザーを作ることができます (4.3.3を思い出してください。存在しないキーに対してハッシュはnilを返すので、:nameキーがなければattributes[:name]はnilになり、同じことがattributes[:email]にも言えます)。
最後に、formatted_emailメソッドを定義しましょう (4.2.2)。このメソッドは、文字列の式展開を利用して、@nameと@emailに割り当てられた値をユーザーのメールアドレスとして構成します。
def formatted_email
"#{@name} <#{@email}>"
end
@ 記号によって示されているとおり、@nameと@emailは両方ともインスタンス変数なので、自動的にformatted_emailメソッドで使えるようになります。
Railsコンソールを起動し、example_userのコードをrequireして、自作したクラスを試しに使ってみましょう。
>> require './example_user' # example_userのコードを読み込む方法
=> true
>> example = User.new
=> #<User:0x224ceec @email=nil, @name=nil>
>> example.name # attributes[:name]は存在しないのでnil
=> nil
>> example.name = "Example User" # 名前を代入する
=> "Example User"
>> example.email = "user@example.com" # メールアドレスを代入する
=> "user@example.com"
>> example.formatted_email
=> "Example User <user@example.com>"
上のコードで、requireのパスにある’.’は、Unixの “カレントディレクトリ” (現在のディレクトリ) を表し、’./example_user’というパスは、カレントディレクトリからの相対パスでexample_userファイルを探すようにRubyに指示します。次のコードでは空のexample_userを作成します。次に、対応する属性にそれぞれ手動で値を代入することで、名前とメールアドレスを与えます (リスト 4.17でattr_accessorを使っているので、これで代入できるようになります)。次のコードは、
example.name = "Example User"
@name変数に"Example User"という値を設定します。同様にemail属性にも値を設定します。これらの値はformatted_emailメソッドで使われます。
4.3.4では、最後のハッシュ引数の波カッコを省略できることを説明しました。それと同じ要領でinitializeメソッドにハッシュを渡すことで、属性が定義済みの他のユーザを作成することができます。
>> user = User.new(name: "Michael Hartl", email: "mhartl@example.com")
=> #<User:0x225167c @email="mhartl@example.com",
@name="Michael Hartl">
>> user.formatted_email
=> "Michael Hartl <mhartl@example.com>"
これは一般にマスアサインメント (mass assignment) と呼ばれる技法で、Railsアプリケーションでよく使われます。例えば第7章は、実際にハッシュ引数を使ってオブジェクトを初期化するコードがあります。
演習
- Userクラスで定義されているname属性を修正して、first_name属性とlast_name属性に分割してみましょう。また、それらの属性を使って "Michael Hartl" といった文字列を返す
full_nameメソッドを定義してみてください。最後に、formatted_emailメソッドの@nameの部分を、full_nameに置き換えてみましょう (元々の結果と同じになっていれば成功です) - "Hartl, Michael" といったフォーマット (苗字と名前がカンマ+半角スペースで区切られている文字列) で返す
alphabetical_nameメソッドを定義してみましょう。 full_name.splitとalphabetical_name.split(', ').reverseの結果を比較し、同じ結果になるかどうか確認してみましょう。
4.5 最後に
以上で、Ruby言語の概要の説明を終わります。第5章では、この章で学んだ内容をサンプルアプリケーションの開発に活かしていきます。
4.4.5で作成したexample_user.rbファイルは今後使わないので、削除してください。
$ rm example_user.rb
次に、その他の変更はリポジトリにコミットして、masterブランチにマージしましょう。
$ git commit -am "Add a full_title helper"
$ git checkout master
$ git merge rails-flavored-ruby
慣習的なチェックとして、リモートリポジトリにpushしたりHerokuにデプロイする前に、テストスイートを流して既存の振る舞いに影響がないかを (念のため) 確認しておきます。
$ rails test
その後、Bitbucketにプッシュし、
$ git push
最後に、Herokuにデプロイして本章は終了です。
$ git push heroku
4.5.1 本章のまとめ
- Rubyは文字列を扱うためのメソッドを多数持っている
- Rubyの世界では、すべてがオブジェクトである
- Rubyでは
defというキーワードを使ってメソッドを定義する - Rubyでは
classというキーワードを使ってクラスを定義する - Railsのビューでは、静的HTMLの他にERB (埋め込みRuby: Embedded RuBy) も使える
- Rubyの組み込みクラスには配列、範囲、ハッシュなどがある
- Rubyのブロックは (他の似た機能と比べ) 柔軟な機能で、添え字を使ったデータ構造よりも自然にイテレーションができる
- シンボルとはラベルである。追加的な構造を持たない (代入などができない) 文字列みたいなもの
- Rubyではクラスを継承できる
- Rubyでは組み込みクラスですら内部を見たり修正したりできる
- 「deified」という単語は回文である
app/helpers/static_pages_helper.rbになります。今回の場合、full_titleヘルパーはサイトのすべてのページで使うことを前提にしていますが、Railsにはこのような場合のための特別なヘルパーファイルapp/helpers/application_helper.rbがあります。nanoは初学者にうってつけではありますが、筆者は普段Vimというエディタを使うことが多いです。使い方が知りたい? 『テキストエディタ編』をどうぞ! (訳注: 他のチュートリアルも日本語にしていく予定ですので、今しばらくお待ちください!)"foo $bar"のようなドル記号による自動的な挿入を連想して比較することでしょう。full_titleヘルパーをビューで利用できるようにする方法などがそうです。provideメソッドは内部で文字列オブジェクトをSafeBufferオブジェクトに変換してしまうので、注意が必要です。つまり、実は文字列オブジェクトではないため、ビューの中で式展開を使うと多くのエスケープ処理が実行されてしまう、ということです。例えば「Help’s on the way」は「Help&#39;s on the way」といった具合にエスケープされてしまいます (この問題を指摘いただいたJeremy Fleischmanに感謝します)。secondメソッドは、実はRuby自身の一部ではなく、Railsが追加したものです。このコードが動作するのは、RailsによるRubyの拡張がRailsコンソールによって自動的に反映されるからです。pメソッドは画面出力だけでなく戻り値もオブジェクトになります。しかし、putsメソッドの場合は引数によらず必ずnilが戻り値になります。(指摘してくれたKatarzyna Siwekに感謝します)View > Ruler > 78、またはView > Ruler > 80で設定できます。
Railsチュートリアルは YassLab 社によって運営されています。
コンテンツを継続的に提供するため、書籍・動画・質問対応サービスなどもご検討していただけると嬉しいです。
研修支援や教材連携にも対応しています。note マガジンや YouTube チャンネルも始めたので、よければぜひ遊びに来てください!