Ruby on Rails チュートリアル








HTML
HTMLの操作を
学ぶチュートリアル
- 第1章HTMLの基礎
- 第2章indexページに手を加える
- 第3章ページを追加してさまざまなタグを学ぶ
- 第4章インライン方式のスタイル追加とCSS
著者について
マイケル・ハートル(Michael Hartl)は、ウェブ開発の主要な入門書の一つである「Ruby on Railsチュートリアル」の作成者です。また、「Learn Enough」の共同創立者であり、主執筆者でもあります。以前は、カリフォルニア工科大学(Caltech)で物理学の講師をしており、そこで生涯功労賞(Lifetime Achievement Award for Excellence in Teaching)を受賞しています。ハーバード大学を卒業後、カリフォルニア工科大学で物理学博士号を取得。Y Combinator起業家プログラムの卒業生でもあります。
Learn Enoughの共同創設者Lee Donahoeは、起業家とデザイナーの顔も持つフロントエンド開発者です。「Learn Enough」「Softcover」「Ruby on Rails Tutorial(英語サイト)」のデザインを手掛けたほかに、「Coveralls」の共同創設者兼フロントエンド開発者でもあり、米国ABCテレビの人気番組Shark Tankでも紹介された紳士服企業「Buck Mason」のリードテストカバレッジアナリスト兼テック共同創設者でもあります。USC(南カリフォルニア大学)卒(専攻:経済学、研究:インタラクティブマルチメディア技術)。
著作権とライセンス
Railsチュートリアル Copyright © 2020 by Michael Hartl(最終更新日: 2023/05/10 07:24:57 PT)
Railsチュートリアルで掲載しているすべてのソースコードは、MIT ライセンスおよびBeerware ライセンスの元で提供されています。なお、これらのライセンスはいずれか一方が有効になります。つまり、MITライセンスに基づいて使用する場合は、ビールも購入する必要はありません。
なお、「すべてのソースコード」とは、Railsチュートリアル内で題材としている「Railsアプリケーションのソースコード」を指します。「Railsチュートリアル」という教材は上記ライセンスで提供されていないのでご注意ください。営利・非営利問わず、事業で使用する場合は教材連携サービスをご利用ください。
The MIT License
Copyright (c) 2016 Michael Hartl
Permission is hereby granted, free of charge, to any person
obtaining a copy of this software and associated documentation
files (the "Software"), to deal in the Software without restriction,
including without limitation the rights to use, copy, modify,
merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES
OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
DEALINGS IN THE SOFTWARE.
THE BEERWARE LICENSE (Revision 42)
Michael Hartl wrote this code. As long as you retain this
notice you can do whatever you want with this stuff.
If we meet some day, and you think this stuff is worth it,
you can buy me a beer in return.
第1章HTMLの基礎
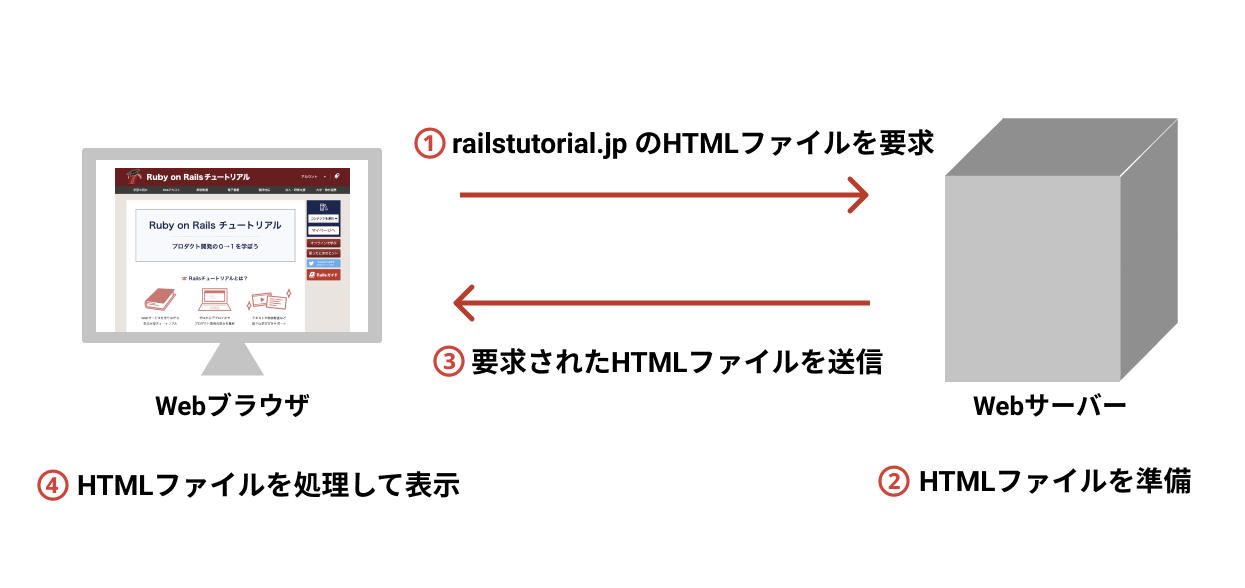
HTMLは「HyperText Markup Language」の略で、World Wide Web(WWW)1で全面的に用いられている「マークアップ言語2」です。ブラウザでWebサイトを開くたびに、そのサイトのWebサーバーがHTMLをブラウザに送信し、ブラウザはそのHTMLをWebページとして画面上にレンダリング(rendering: 描画)します(図 1.1)。この処理方法は世界中で普遍的に用いられているので、Web技術を業務で使う人々3なら誰でも、「HTMLとは何か」「HTMLのしくみ」を学ぶ意義があります。本書『HTML編』は、こうしたHTMLの基礎部分をしっかり学べるように構成されています。
インターネット上ではさまざまなHTMLチュートリアル的な教材を見つけられますが、そうした教材の多くは個別のHTML構文のサンプルや解説が中心で、「現場で役立つHTMLを実際に書く方法」や「書いたHTMLのデプロイ4方法」まではなかなか手が回らないのが現状です。本書では、本物と同じHTMLページの具体的な作り方はもちろん、作ったHTMLページを実際のWebサーバーにデプロイする方法についても、手順を追って進めれば必ず最後までたどり着けるように構成されています。「HTMLのすべてをまとめて学ぶ」体験を得られるので、HTMLを初めて学ぶ方はもちろん、既に他のHTMLチュートリアルをやってみたことのある方にもおすすめです。本チュートリアルでの学習内容には、皆さんのスキルを伸ばすために重要な「技術の成熟」も含まれています(コラム 1.1)。
本チュートリアルでは、HTML全体を隅から隅までもれなく解説することはしません。その代わりHTMLを正しく、サクサク書けるようになるために必要なポイントに絞って解説します。ここで言う必要なポイントには、「わからないことがあったら自分で調べる」のに不可欠な基礎知識や調べ方も含まれます。概念を表す具体的な用語を学び、「どこがわからないか」「どこまではわかっているか」を自分の中ではっきりさせておかないと、インターネットで検索することもできません。そうした「わからないことを自力で調べて解決するスキルを獲得する」ことは、本チュートリアルシリーズ全体の重要な主題でもあります。
技術というものが新しいリテラシーだとすれば、技術の成熟(technical sophistication)は「読み書きのスキルを身に付ける」ことと似ています。技術の成熟には、本を声に出して読むときのように「自分の力で理解する」スキルや、必要に応じて辞書を参照しながら文を書くときのように「自分の力で調査する」スキルも含まれます。
HTMLは、Web技術で欠かすことのできない「書き文字」であり、学校で習う「ひらがな」「カタカナ」「漢字」に匹敵する必須科目です。
本書では、皆さんの「技術の成熟」をレベルアップする機会を要所要所に織り込んでいます。作成したWebサイトはただちにproduction(本番)環境にデプロイし(1.3)、デプロイでつまづきがちな問題の解決方法も合わせて学びます。まだよくわからないHTMLコードが登場したら、まずざっくり読んで大体の内容を把握するにとどめ、詳しい内容についてはその後で学びます。また本チュートリアルでは、最初からプロフェッショナル級の品質でHTML Webサイトを「正しい方法で」学ぶために、コマンドライン編、テキストエディタ編、Git/GitHub編で皆さんが学んだツールを総動員します。
実用性を重視するため、本チュートリアルで用いるのはすべて「ガチのプロ向け」ツールです(図 1.2)。これらのツールについては、本チュートリアルシリーズで順に学んだものをそっくりそのまま使います。以下のツールの理解や使いこなしに不安のある方は、本編に取り組む前に予習しておきましょう。
- Unixコマンドラインについては『コマンドライン編』を参照
- テキストエディタについては『テキストエディタ編』を参照
- Gitを使ったバージョン管理については『Git/GitHub編』を参照
本チュートリアルは「ソフトウェア開発のベストプラクティス」「実際のWebサイトにデプロイする具体的な手順」までも網羅し、この1冊でHTMLのスキルを完結して学べるようになっています。HTMLをまったくのゼロから学ぶ方にとっては少し敷居の高い内容ですが、会得するメリットは計り知れないほど大きなものになります。本編を学んでおけば、他の開発者と共同作業するうえでも、さらに複雑なWebサイトの構築方法を学ぶスキルを身につけるうえでも、絶大なメリットがあります。
本書では、HTMLの何もかもを学ぶのではなくHTMLの核心部分を理解することを中心に据えています。第1章ではいわゆる「hello, world!」ページをいきなりproduction環境にデプロイするところから始めます。第2章では、indexページに「書式(フォーマット)付きテキスト」「リンク」「画像」を入力する方法を学び、さらに第3章で、サイトのページを増やして「テーブル」や「リスト」などの高度な機能を盛り込みます。最後に第4章で「インラインスタイル」も多少追加し、素のHTML要素にシンプルなスタイルを適用するとどんな効果が現れるかを実際に確かめながら学んでいきます。
本編を通して構築するWebサイトはもちろん実際に正しく動作しますが、チュートリアルが終盤にさしかかる頃には、HTML単体だけでは解決できない重要な制限がいくつか登場し始めます。これは、本編の次の段階である『CSS & Design編』に進むための準備でもあります。
次のチュートリアルでは、CSS(Cascading Style Sheets)を用いて最新の完全なWebサイトを作成し、サイトのデザインをHTML構造から切り離します。また、Webサイトのレイアウトを構成する方法や、高度なスタイル作成方法についても合わせて学べます。
1.1 はじめに
どんなシンプルなWebサイトも、どれほど複雑なWebサイトであっても、舞台裏を支えているのはHTMLです。本チュートリアルでは、シンプルかつ「本物の」プロ仕様Webサイトを実際に作ってデプロイしながら、あらゆるWebサイトでコンテンツの編成やオンライン表示の舞台裏を支えている構造を学びます。
HTMLは、世界最初5の「Web開発者」であるTim Berners-Lee(図 1.3)6によって1993年に導入されて以来、技術標準として絶え間なく進化を繰り返してきました。長い間「HTMLに何があるか」「HTMLに何がないか」という仕様をW3C(World Wide Web Consortium)と呼ばれる団体が管理していましたが、2021年1月にはW3CのHTML5は廃止され、WHATWGのHTML Living Standard7が正式にW3Cで勧告として発表されました。詳しくは『どうしてHTML5が廃止されたのか』をご覧ください。
Webブラウザを作っている企業は、規定の仕様を参照して、「テキストをボールド(太字)にする」指定や「文字色を変える」指定、あるいは「両方同時に行う」指定などが正しい形式でブラウザに渡されたときに期待どおりに振る舞うよう、ブラウザを実装します。

心配しないで欲しいのですが、HTMLのバージョンが変わるごとに何が変わったのかを細かく調べる必要はありません。ブラウザの機能を拡張して最新技術を取り入れるために、機能の「変更」ではなく単に新機能を定期的に「追加」していることを知っておけば十分です。機能変更より機能追加の方がずっとやりやすいのです。現に、HTMLでよく用いられるさまざまな「要素(element)」は、本チュートリアルで全般的に用いている要素も含め、これまで当初の仕様からほとんど変更されていません。
ただし、そうした要素が何の心配もなく常に安全に使えるとは限りません。というのも、HTMLの仕様は「コミッティー(committee: 委員会)」によって組み立てられた、絶え間なく進化を繰り返す異形のクリーチャーでもあるからです(図 1.4)8。具体的ないくつかの事例については「1.2」で解説します。

1.2 HTML タグ
HTMLは「HyperText Markup Language」という名前が表すとおり、「マークアップ言語」の一種です。マークアップ言語は、プログラミング言語では「ありません」のでご注意ください。
Webサイトの作者は、HTMLを用いて「コンテンツをどう表示すべきか」を編成および定義できます。具体的には、テキストを太字やイタリックにするなどの「書式(formatting)」を指定したり、「見出し(heading)」「リスト(list)」「テーブル(table: 表)」「画像」「リンク」をコンテンツに追加したりできるということです。
HTMLファイルは、普通のテキストドキュメントに著者がさまざまな注釈を注意深く追加したもの、と考えるとよいでしょう。こうした注釈には「この部分を強調表示(highlight)したい」「ここに画像を置きたい」「ここで追加情報の置き場所を読者に見せたい」といったものがあります。
HTMLのH、つまり「ハイパーテキスト(Hypertext)」とは、Web上のドキュメントから別のドキュメントへ(直線的でない方法で)表示を移動するリンク方法のことです。たとえば、Wikipediaで「HTML」の記事を読んでいると、CSSのような関連トピックへのリンクが強調表示されているとします。このリンクをクリックすると、表示はただちにその別記事に移動します。また、Wikipediaの特定のページにリンクする代わりに、WikipediaのWebサイトそのものにリンクすることもできます。なお、ドキュメントの外部リンクをクリックすると、ブラウザ上でそのページが新しいタブとして表示されることがありますが、これを行う方法については「3.3」で学びます。
ハイパーテキストは、従来のリンクなしドキュメントと比べて技術的に大きな進歩です。探したいものを見つけるのに、紙のようにページをめくったり、Webページを延々下にスクロールしたりせずに済むのです。今やドキュメント間をリンクする機能は「あるのが当たり前」ですが、HTMLの仕様が作成された当時は、技術史にその名を残すに値する大発明だったのです。
HTMLのソースコードは「プレーンテキスト(plain text: 素のテキスト)」形式で書かれます。『テキストエディタ編』で解説したように、プレーンテキスト形式はテキストエディタで編集するのにうってつけです。
ワープロソフトやリッチテキスト形式(RTF)などのWYSIWIG9アプローチは、人間がドキュメントにGUI10やメニューで直接書式を設定できる点は便利ですが、書式をコンピュータで手軽に自動変更するといった柔軟な処理には不向きです。
HTMLではその代わりに特殊な「タグ(tag)」を用いて書式を指定します(図 1.5)11。先ほど説明した「テキストへの注釈」とは、タグのことなのです。

後ほど説明しますが、HTMLでサポートされているタグにはさまざまな種類があります。しかし基本的なタグは、以下のように「開始タグ」「文字列」「終了タグ」の形式になります。なお、文字列(string)とは「文字(character)の集まり(sequence)」のことです。
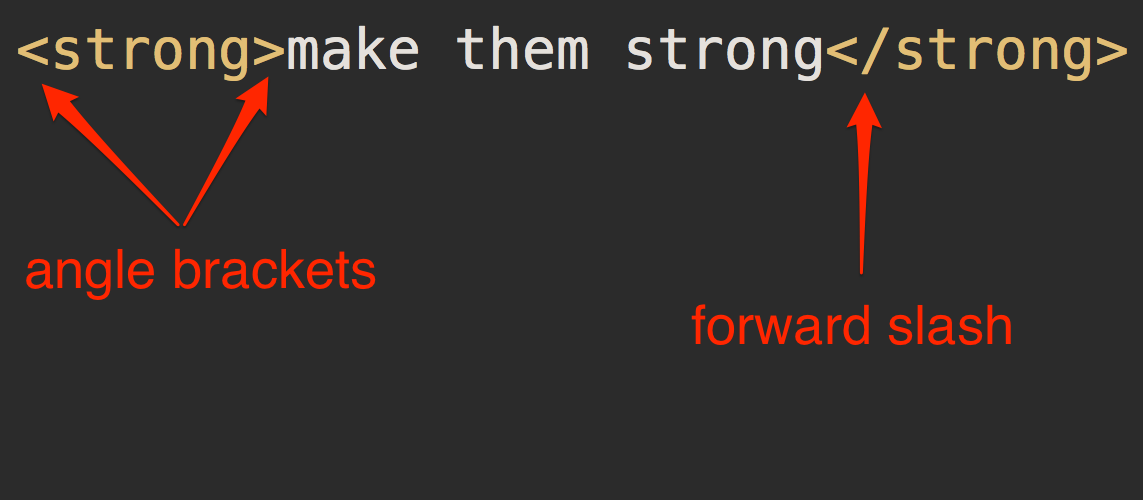
<strong>make them strong</strong>
この典型的なタグの構成を、図 1.6で詳しく説明します。この図には、「タグの名前」(ここではstrong)、「山かっこ(angle brackets)」記号(<と>)、そして「スラッシュ(forward slash)」記号(/)があります。
HTMLタグは、エンドユーザー(つまりWebサイトを見ている人)のWebブラウザ画面には表示されませんが、舞台裏でブラウザに対して「コンテンツにどう書式を設定するか」「ページ上でどのように表示すべきか」を指示します。strongタグのシンプルな例をリスト 1.1に示します。
これは文字列です。文字列の中には、重要な部分もあれば重要でない部分もありますが、読者が重要な部分に注目してくれるように
したいと思います。そこで、文字列の一部を<strong>強調表示に変更</strong>して、文字列の他の部分より浮き立つようにした
いと思います。
strongタグは、ほとんどのブラウザでボールド(太字)のテキストとしてレンダリング(表示)されます。つまりリスト 1.1は典型的なブラウザ上で以下のような感じで表示されます12。
これは文字列です。文字列の中には、重要な部分もあれば重要でない部分もありますが、読者が重要な部分に注目してくれるようにしたいと思います。そこで、文字列の一部を強調表示に変更して、文字列の他の部分より浮き立つようにしたいと思います。
ところで、HTMLではstrongタグの他にボールド用のbタグも「一応」サポートされています。しかし近年のHTMLでは、このbタグやiタグのような「ナマの書式を指定するタグ名」を仕様でこれ以上増やさないようにしており、その代わりに「意味」(堅苦しく言うとsemantics: セマンティクス)を中心に据えたタグ名、いわゆる「セマンティックタグ(semantic tag)」を使うようになっています(コラム 1.2)。たとえば、セマンティックタグであるstrongタグは「そのタグで囲まれたテキストを何らかの形で強調せよ」という指示であり、具体的な強調の方法はブラウザに任されています。
<b>タグや<i>タグにはご用心」というお話
むかしむかしのお話です。HTMLが最初に作られた頃は、インターネットに接続すると「ピー、ガガガガ」というファックスみたいな音がいつも鳴り響いていました。しかもその当時は、インターネットに接続した時間で課金されたり、送信したデータ量で課金されるのが普通でした。要するに今よりもネット接続の料金がずっと高かったのです。
当時はこうした制約があったため、HTMLのタグを決めるときにも「タグをどこまで短くできるか」が重要視されました。つまり、タグの文字数が少ないほど通信料金を節約できるということです。何しろできたての技術でしたので、「タグ名にちゃんと意味がある」かどうかをじっくり考える余裕もなく、「1文字で意味がわかりにくくてもいいの!」「指定どおりに表示できればそれでいいの!」という風潮でした。
このように何とかしてタグを短くしようと頑張った結果、初期のHTMLではテキストをボールドにするときにbタグ(<b>...</b>)、テキストをイタリックにするときはiタグ(<i>...</i>)という、書式を「即物的に」表すタグが使われました(実は今も使われてしまっています)。要するにケチケチ作戦ですが、それでも当時はこれで困る人はいませんでした。
やがて一部の開発者たちが、ひとつ重大なことに気づき始めました。「今のHTMLタグは、ブラウザ上の書式(=見た目)しか定義されていないじゃないか!」「今のHTMLタグは、コンテンツの意味を表す方法が定義されていないぞ!」という批判が始まりました。
ブラウザ上でそれっぽく見えていればそれでOKな人々はそんなことを気にしませんでしたが、大量のWebページを自動的に解析するシステムを作る人々は困難に直面していました。さまざまなタグで囲まれたコンテンツの実際の意味を自動的に推測する必要に迫られていたのです。「ここは本文なのか?」「ここは結論なのか?」「ここは注釈なのか?」「ここは脚注なのか?」「ここは本文と関係ない操作用のGUIなのか?」という具合です。
この問題を解決するため、HTMLの仕様に新しいタグを追加するときには「見た目を表すタグ名」を排除して「文書の構造上の意味を表すタグ名」を推進しようというムーブメントが起こりました。その結果、ボールドはstrongタグ(<strong>...</strong>)で指定し、イタリックはemタグ(<em>...</em>、emはemphasisの略)で表すことが望ましいということになりました。つまり、テキストをボールドにする真の意図は、そのテキストをコンテンツの中で「際立たせたい」ということであり、テキストをイタリックにする真の意図は、そのテキストを「(軽めに)強調したい」ということである、という考えに基づいています13。
大した違いではないだろうと思われるかもしれませんが、セマンティックタグの用途は、単にテキストを際立たせたり軽く強調したりするだけではありません。セマンティックHTMLタグについて詳しくは『CSS & Design編』で解説します。そこでは、常識的なタグの使い方やページレイアウトの作成方法についてさらに深堀りする予定です。
ここまで、HTMLの中核となる概念について解説しました。すなわち「HTMLは、タグで囲まれたコンテンツでできている」「タグはコンテンツを組み立てたり、表示の変更を指定したりするのに使う」ということです。
しかし、神ならぬ悪魔もまた「細部に宿る」ということわざもあります。HTML全体の詳細は果てしがありません。
1.3 プロジェクトを開始する
マークアップとタグの基本的な構造を学び終えたので、いよいよHTML学習用の「サンプルWebサイト」を立ち上げる準備が整いました。このサンプルWebサイトは、「本チュートリアル」「サイトの会社情報」「HTML自体」に関するささやかな情報を提供する模擬的な情報Webサイトで、モックと呼ばれます。このWebサイトに、homeページと2つの補足用ページを開発しながら、さまざまなHTMLタグの使いこなし方を学ぶと同時に、一般公開Webサイトの作り方についても説明します。つまり、あなたの学習の成果がインターネット上で誰でも見れるようになります。今はサンプルの情報をそのまま使いますが、最終的にはこのWebサイトに「あなたの情報」を掲載します。
最初は『Git/GitHub編』のときと同じ手順に沿って進めるので、本セクションはGit操作のおさらいも兼ねています。(Gitの使いこなしに不安があれば今のうちに『Git/GitHub編』を読んでおきましょう。)本セクションを終えると、同チュートリアルと同じくGitHub Pagesで実際に動くWebサイトにサンプルHTMLサイトをデプロイできるようになります(コラム 1.3)。
GitHubに自分のアカウントがあり、自分のメールアドレスがそのGitHubアカウントで確認済みであれば、サンプルHTMLサイトをGitHubのインフラ上にホスティングできる「GitHub Pages」という機能を無料で利用できます。なお「ホスティング(hosting)」とは、Webなどのサービスをデプロイして動かすこと、またはそうした設置の場を提供するサービスです。
Webが登場して間もない頃の不便極まりない時代と比べると、これは夢のように素晴らしい進歩です。同じことを1999年にやろうとしたら、(大学や研究機関などのWebサイトを無料で使うのでもない限り)ホスティングサービスも有料でしたし、Webサイトを閲覧するユーザーにデータが転送されるときの費用まで負担しなければなりませんでした。Webサイトが大して混雑していないのに請求額が急上昇することもありました。
今は当時よりもずっとよい選択肢がいろいろあり、GitHub Pagesもそのひとつです。GitHub Pagesは無料で、しかも驚くほど使い勝手がよいのです。後述する設定を1か所更新すれば、mainブランチからWebサイトをGitHub Pagesで動かせるようになります。無料の『Learn Enough Custom Domains to Be Dangerous』チュートリアル(英語)でも説明しているように、このWebサイトを「www.example.com」のようなカスタムドメインで運用することもできます。つまりGitHub Pagesは、Gitのバックアップが組み込まれたプロ級のハイパフォーマンスWebサイトを、完全に無料で実現しているわけです。
GitHub Pagesだけでこれだけのことができると、他のサービスはちょっとやそっとでは太刀打ちできませんね。
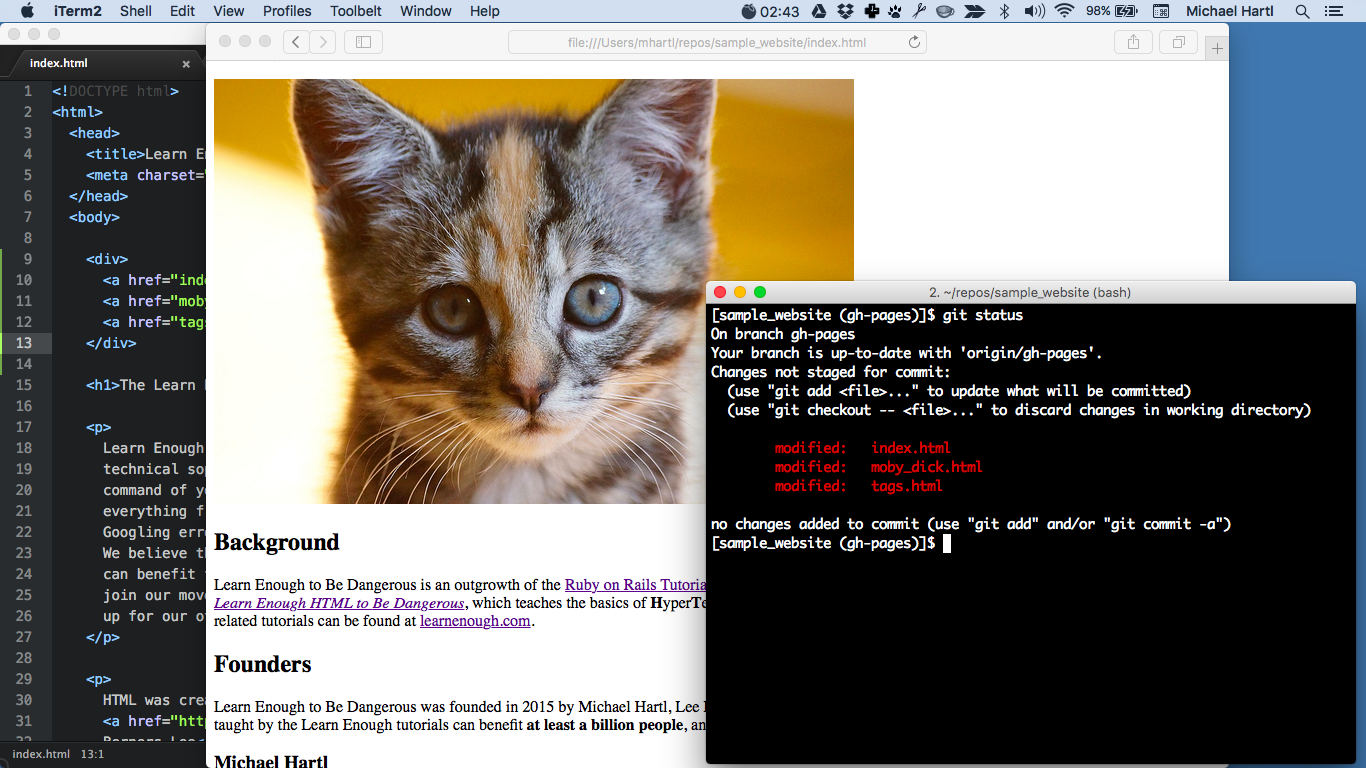
それでは、サンプルWebサイトで使うディレクトリと最初のGitリポジトリを作りましょう。最初に「ターミナル」アプリでウィンドウをひとつ開いて14、sample_websiteというディレクトリを作成します15。
$ mkdir -p repos/sample_website
次は、cdコマンドでディレクトリの中に移動し、touchコマンドでサイトのメインページ用ファイルを作成します。ファイル名はindex.htmlにすべきです16。
$ cd repos/sample_website
$ touch index.html
続いて、Gitリポジトリを作成(初期化)します。
$ git init
$ git add -A
$ git commit -m "Initialize repository"
先ほどtouchコマンドでファイルを作っておいたのには理由があります。ファイルが何も入っていない空のディレクトリは、そのままではGitでコミットできないので、何か適当なファイルを作って入れておく必要があったのです17。
作成するファイル名をindex.htmlにすべきと書いたのにも理由があります。いわゆる「homeページ」に使うデフォルトのファイル名にはindex.htmlを使うことになっています。あるWebサイトのドメイン名のみをブラウザのアドレスバーに入力して開くと、このindex.htmlファイルの内容が自動的にデフォルトとして表示されます。言い方を変えると、たとえばexample.comをブラウザで表示すると、そのWebサイトのサーバーは自動的にexample.com/index.htmlを表示します18。
日本ではWebサイトを指すときに未だに「ホームページ」という言葉が使われることがありますが、この用い方は正確ではありません。本来のhomeページとは、「そのWebサイトを開くと最初に表示される、出発点としての(特定の)ページ」「その中で他のページに移動しても、最終的にそこに戻る(特定の)ページ」を指すものであり、Webサイト全体を指すものではありません。19。本チュートリアルでは、意味の不正確な俗称の「ホームページ」と区別するため「homeページ」と表記しています。
「Webサイトのデフォルトであるhomeページのファイル名はindex.htmlにする」というのは、厳密には絶対的な決まりではなくWeb開発の慣習(convention)に過ぎず、実際にはWebサーバーの設定でいくらでも他のファイル名に変えられます。そもそもなぜhome.htmlにしなかったのかという素朴な疑問もあるかもしれませんが、この慣習はほぼ完全に定着しているので、事実上絶対に近いと考えてよいでしょう20。今後自分でWebサイトを構築するときも、他の開発者が混乱しないよう、この慣習に従っておくことをおすすめします。
example.comというドメイン名は、先ほども述べたようにサンプル用の標準ダミードメインとして予約されています。今後Webサイトを自分で作るときも、何らかのダミードメインをHTMLで書く必要が生じたらこのexample.comを使うよう習慣づけておくことをおすすめします。なぜなら、このダミーサイトは今後変更される心配がなく、安心してダミーに使えるからです。逆に、たとえばusousousouso800.comのような「たぶん存在しないであろうドメイン名」をその場で適当にでっちあげて入力するのは避けましょう。将来誰かが本当にそのドメインを作ってしまうかもしれません。同じ理由で、ダミーのメールアドレスが必要になったときも、このexample.comを使うようにしましょう21。
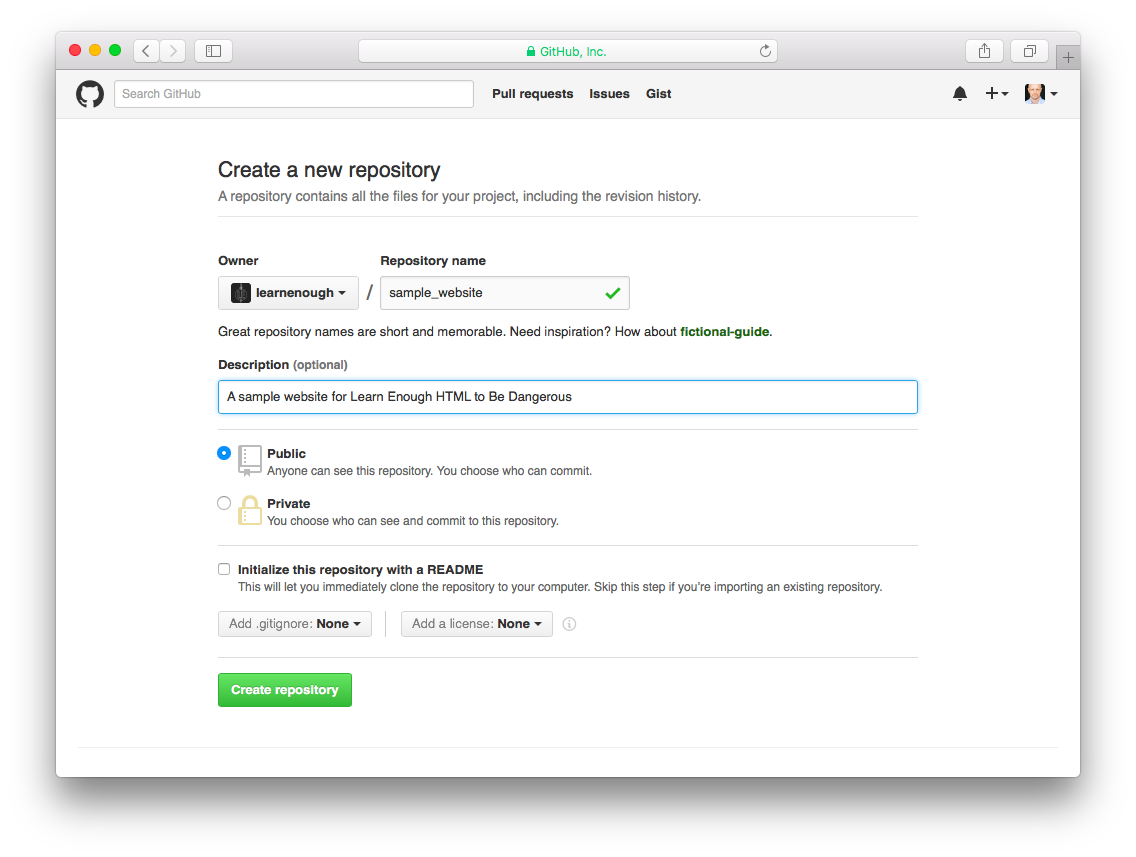
さて、Gitリポジトリを初期化したので、リポジトリをGitHubにpushする準備が整いました(リポジトリは空っぽ同然ですが)。『Git/GitHub編』で解説したように、github.comをブラウザで開いてログインし、そこでsample_websiteというリポジトリを新規作成し(図 1.7)、「A sample website for Learn Enough HTML to Be Dangerous」という説明文(description)をそこに入力します(図 1.8)22。
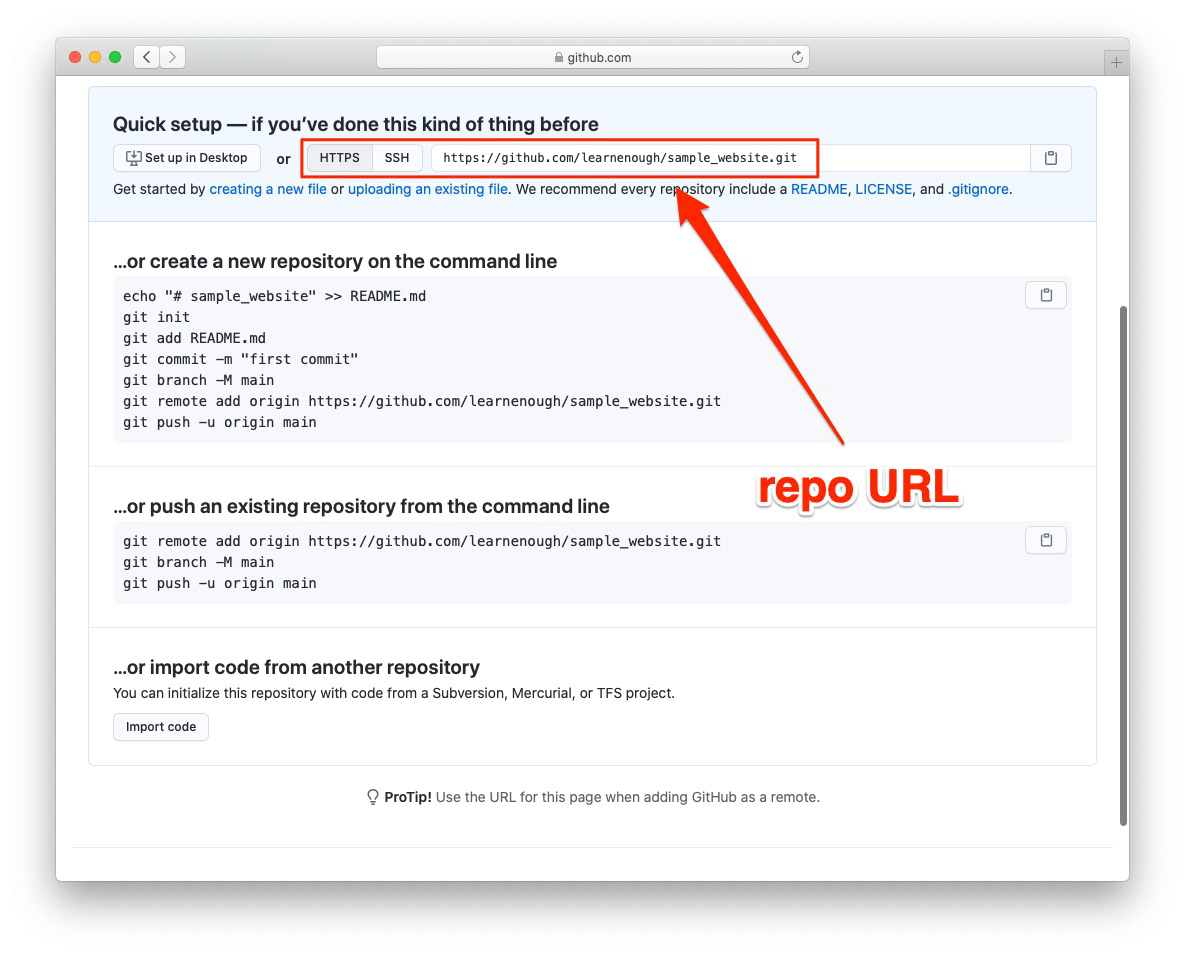
リモートリポジトリができたら、そのリモートリポジトリのURLを、手元のローカルリポジトリの「リモートオリジン(remote origin: リモートの取得元を指す)」にメインのURLとして設定します。リモートリポジトリのURLは図 1.9に示した場所にあります。なお、同じGitHubセットアップページの「…or push an existing repository from the command line」セクションに表示されているコマンドをコピーして使っても構いません。
$ git remote add origin <リモートリポジトリのURL>
$ git push -u origin main
このとき、パスワードの入力を求められます。このパスワードはGitHubのパスワードではなく、個人用のアクセストークンにする必要があります。詳しくはGit/GitHub編「2.2 リモートリポジトリ」をご覧ください。
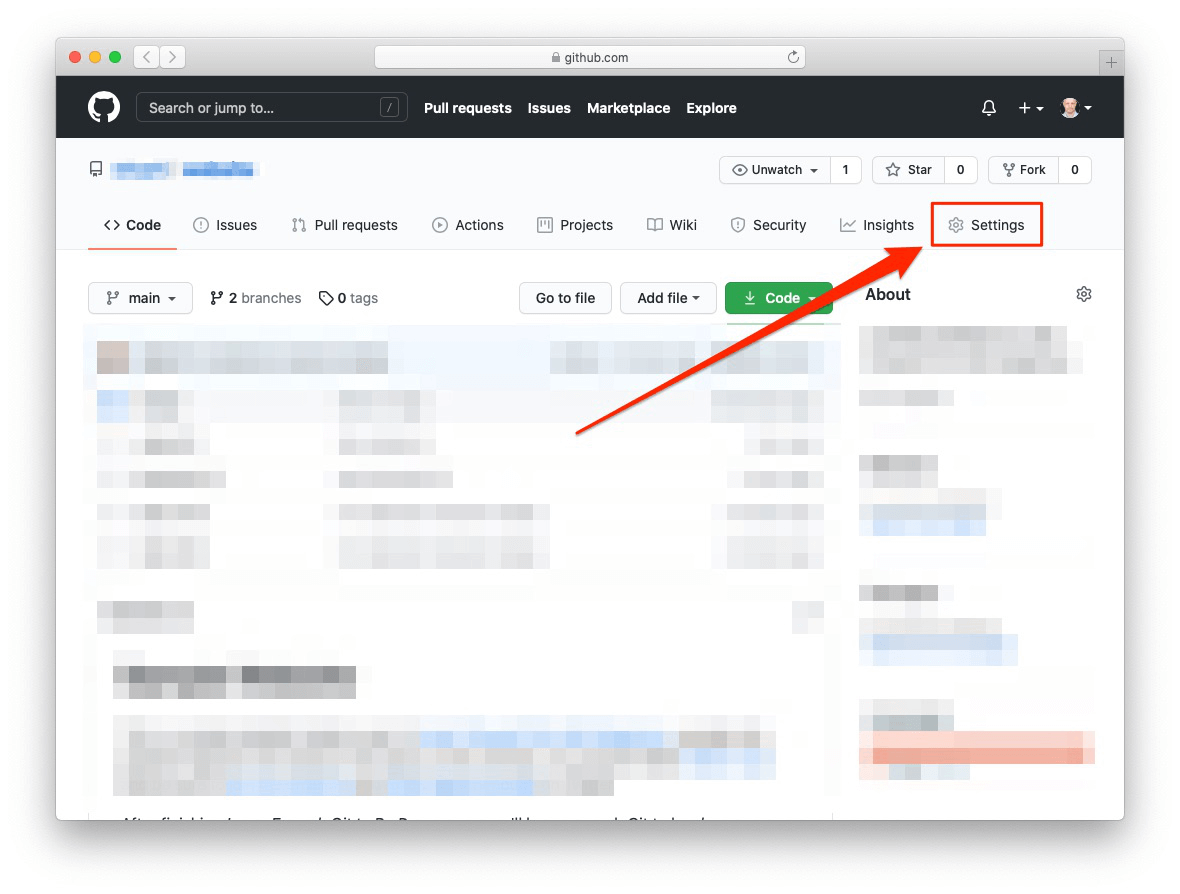
この時点で、『Git/GitHub編』の「4.4 とっておきのボーナス」で解説したときと同じように、mainブランチをWebサイトとして公開する準備をします(図 1.10、図 1.11、図 1.12)。
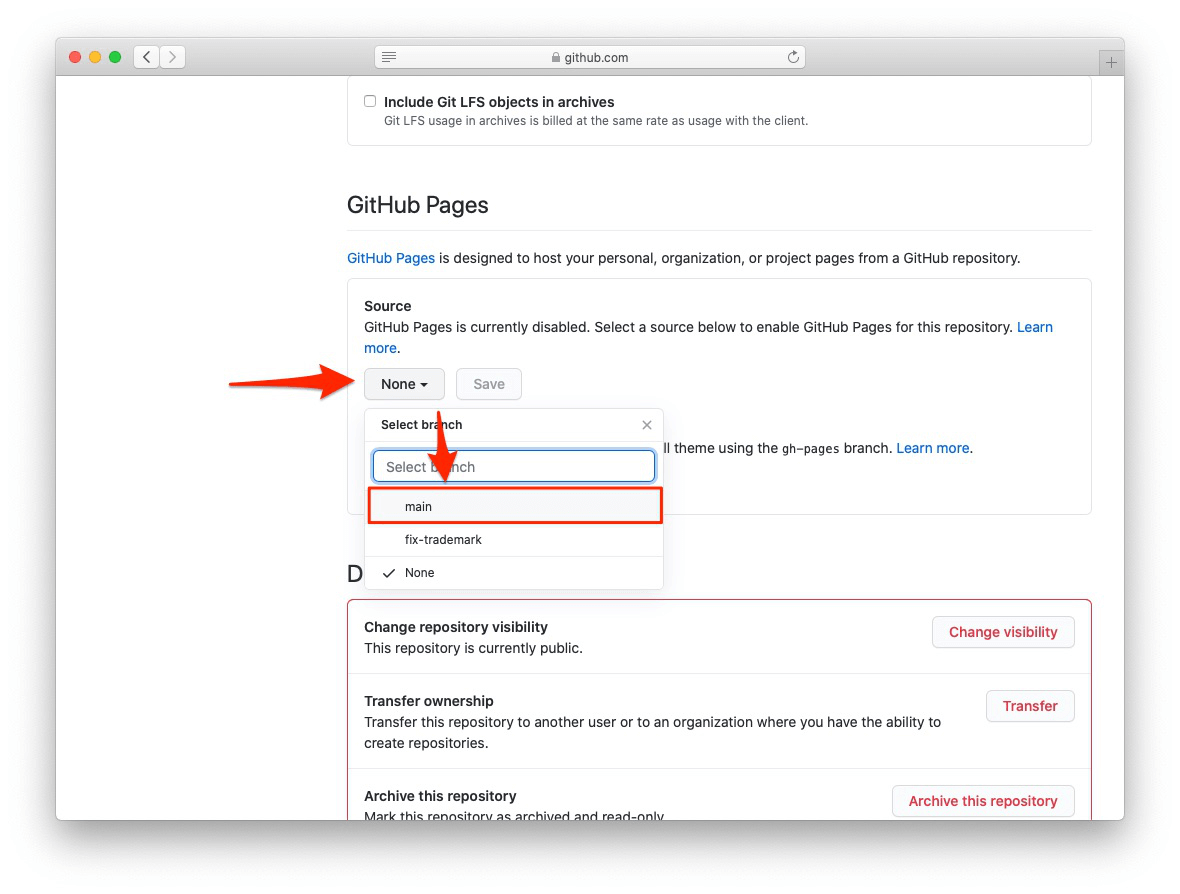
mainブランチをWebサイトとして公開する
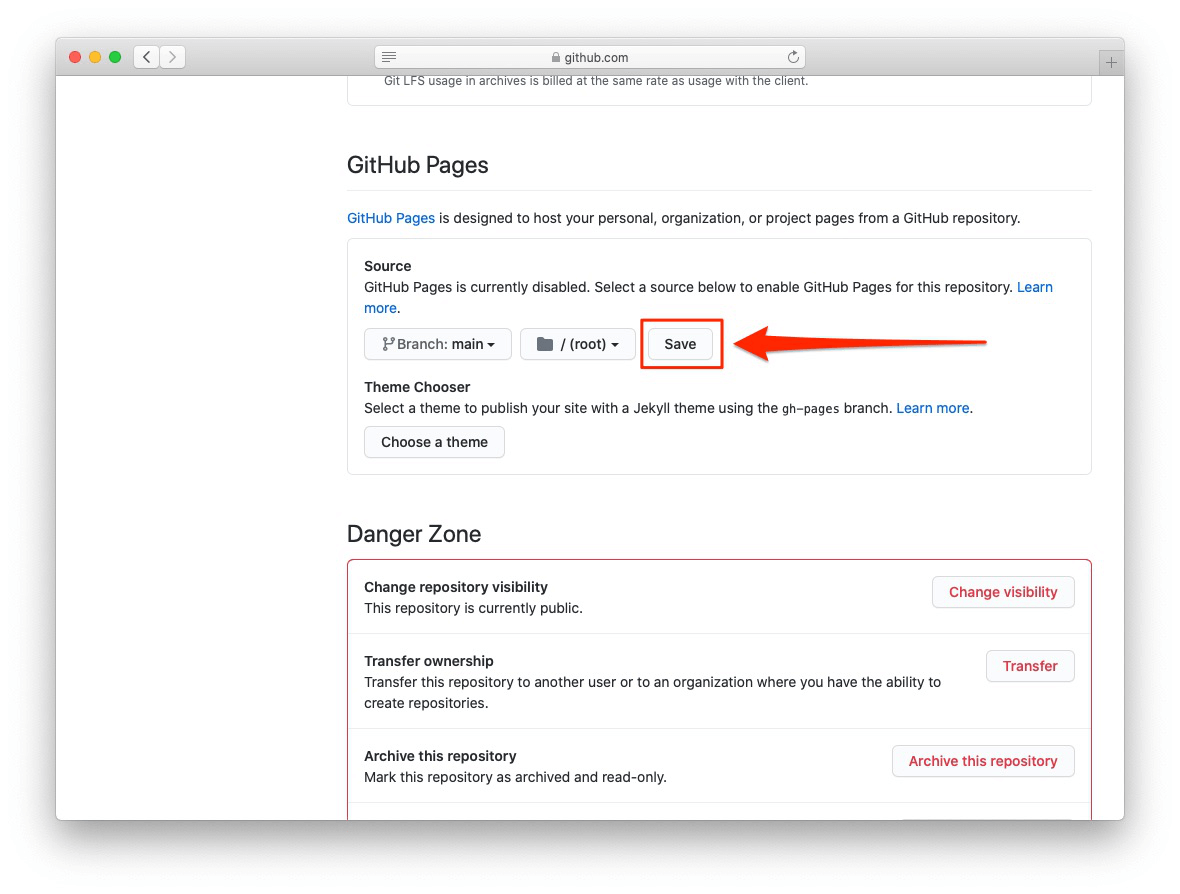
たったこれだけの手順で、サンプルWebサイトがGitHub Pages上で動くようになりました!サンプルWebサイトのURLは、github.ioドメインであなたのユーザー名とリポジトリ名を元に自動的に与えられます(リスト 1.3)。
https://<ユーザー名>.github.io/<リポジトリ名>
たとえばLearn EnoughのサンプルWebサイト(英語版)は、以下のURLで今も動いています。
https://learnenough.github.io/sample_website_reference_implementation
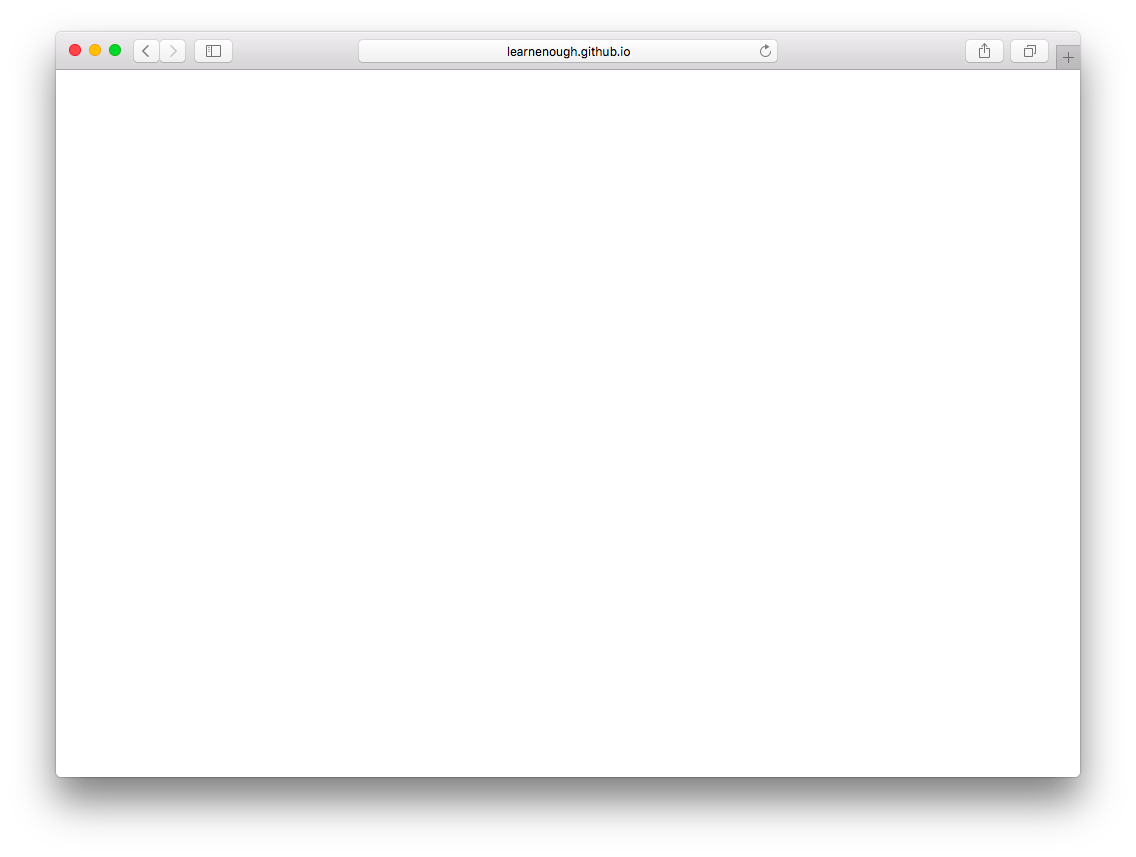
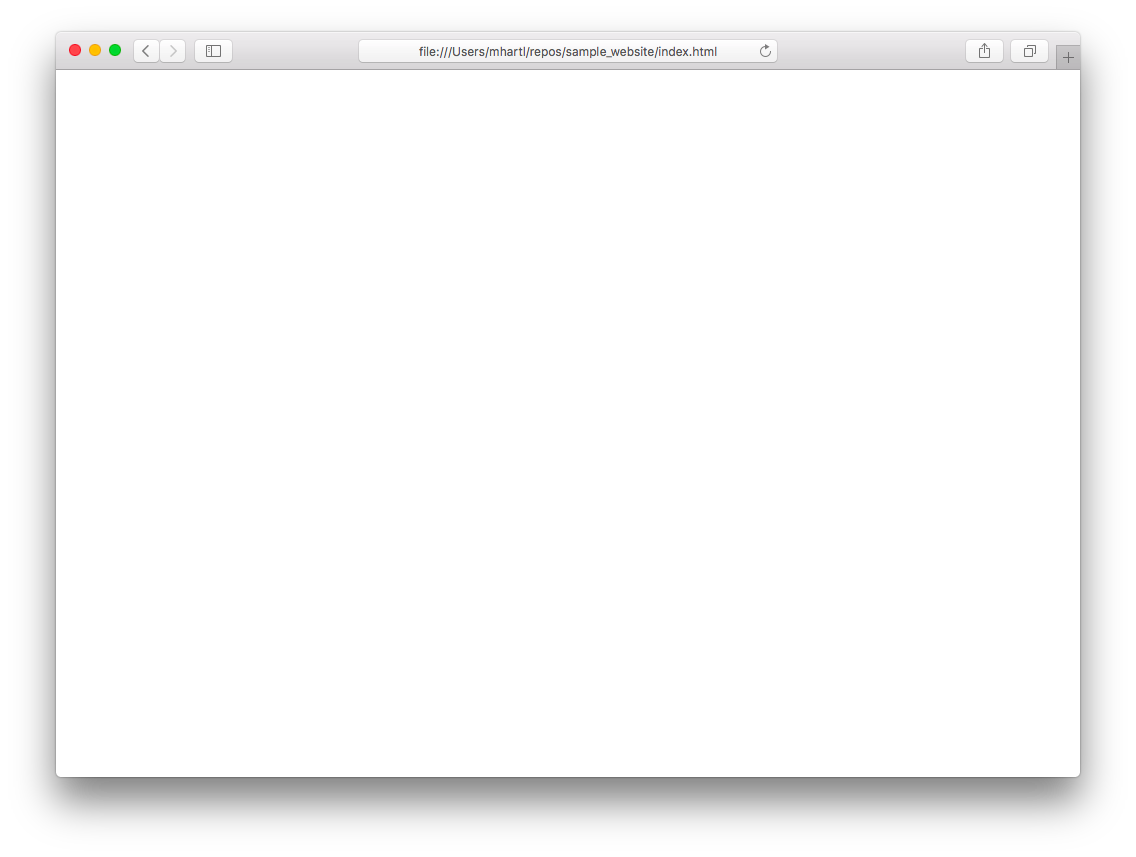
皆さんが作ったサイトのURLをブラウザで開くと、ドメイン名が正しく解決され、index.htmlファイルの内容が自動的にブラウザに表示されるはずです。ただし現時点ではコンテンツが空なので、ブラウザ表示も空っぽです(図 1.13)。このままでは悲しすぎますが、この後「1.4」で変更を加え、さらに第2章で急加速する予定ですのでご安心ください。
1.3.1 演習問題
-
README.mdというファイルを追加してコミットしてください。ファイルは空のままにせず、Markdownタグを数個入れること。最後にGitHubのリポジトリをブラウザで表示して、何が変わったかをチェックしてください。 - ブラウザで
<ユーザー名>.github.io/<リポジトリ名>/README.mdを開いて、何が表示されるかを確認してください。また「パブリックなWebサイトリポジトリに個人情報を含めるとどうなるか」についてあなたの考えを述べてください。
1.4 最初に学ぶタグ
1.3でGitリポジトリを初期化するために、空のindex.htmlファイルを作りましたが、このサンプルWebサイトには最終的にさらにファイルを追加することになります。本セクションでは、手始めに1つのタグの中にコンテンツを追加することにします。その後コミットしてデプロイすれば、Webサイトで見れるようになります。単純なことに見えるかもしれませんが、これは大きな進歩であり、この先を学ぶうえで欠かせない基礎となります。
空のindexページができたので、自分の好きなエディタでこのindex.htmlを開きましょう。本チュートリアルではVSCodeをエディタとして使います。「File > Open」メニューを使えばディレクトリを開くこともできますが、『テキストエディタ編』で解説したように、クールにキメるなら次のようにコマンドラインを用いてHTMLプロジェクトディレクトリ全体を一発で開くのが普通です(図 1.14)23。
$ code .
なおエディタがSublime Textの場合は「subl .」でできます。このドット「.」はカレントディレクトリを指すと『コマンドライン編』で学んだことを思い出しましょう。

ファイルがまだ1つしかない状態であっても24、このようにプロジェクト全体をコマンドラインで開く習慣を身につけておくのはよいことです。こうしておけば、同じプロジェクトにある複数のファイルを同時に開くのも簡単になります。今後3.1でページを追加するときにもこの技を使う予定です。
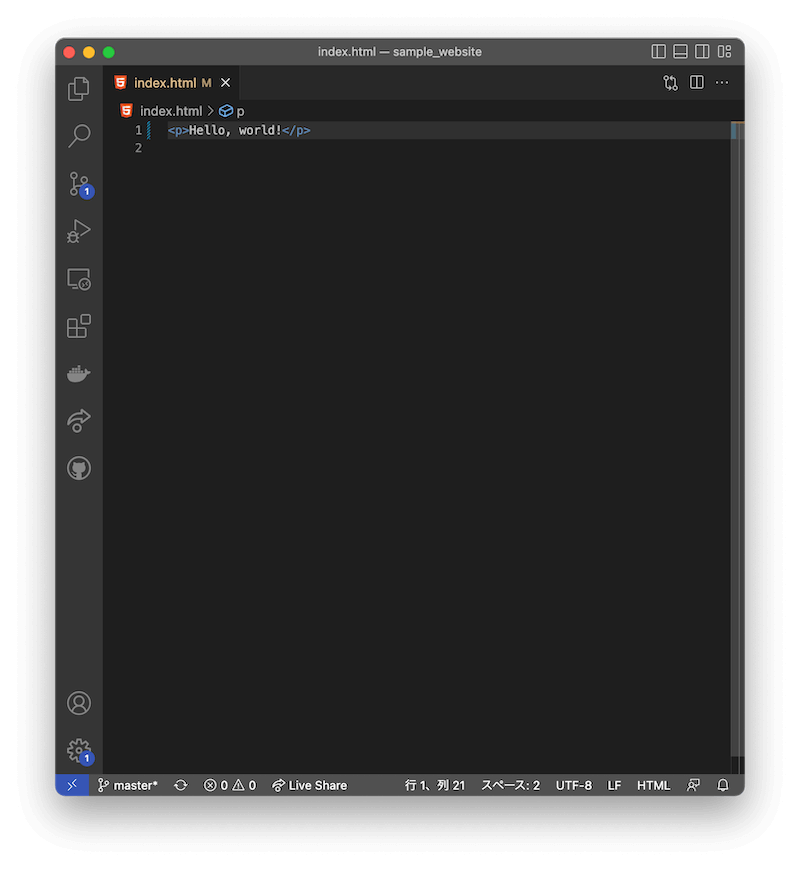
とりあえず今はindexファイルにコンテンツを追加できる状態になっています。そのコンテンツとは「Hello, world!」というフレーズをpタグで囲んだものです(リスト 1.4)。なお、pは「パラグラフ(paragraph: 段落)」のことです。pタグで囲むときは、strongタグのときとまったく同様に、開始タグ<p>と終了タグ</p>で囲む必要があります(図 1.6)。
index.html
<p>Hello, world!</p>
エディタに表示されるHTMLソースコードは、図 1.15のように自動的にハイライトされます25。この「シンタックスハイライト(syntax highlighting)」機能は、人間がソースコードを読みやすくするためのもので、コンピュータのためではありません。シンタックスハイライトは、index.htmlファイル自体には何の影響も与えませんが、エディタ上でタグとコンテンツを色分けして人間が楽に区別できるようにしています。本チュートリアルのコード例がシンタックスハイライトで色分けされているのもそのためです。
index.htmlにコンテンツを追加したので、ブラウザで結果を確認しましょう。macOSの場合は、以下のようにコマンドラインでopenコマンドを実行します。
$ open index.html # macOSでのみ有効
Linuxシステムの多くは、xdg-openという似たコマンドが使えます。
$ xdg-open index.html # Linuxでのみ有効
sample_websiteディレクトリをGUIのファイルブラウザ(macOSならFinder、Windowsならエクスプローラ)で開いてファイルをダブルクリックする方法は、ほとんどのOSで共通に使えます(図 1.16)。
index.htmlファイルをダブルクリックするとデフォルトのブラウザで開かれる
どの方法を使ったとしても、最終的にindex.htmlファイルがデフォルトのブラウザで開かれて、図 1.17のように表示されるはずです。
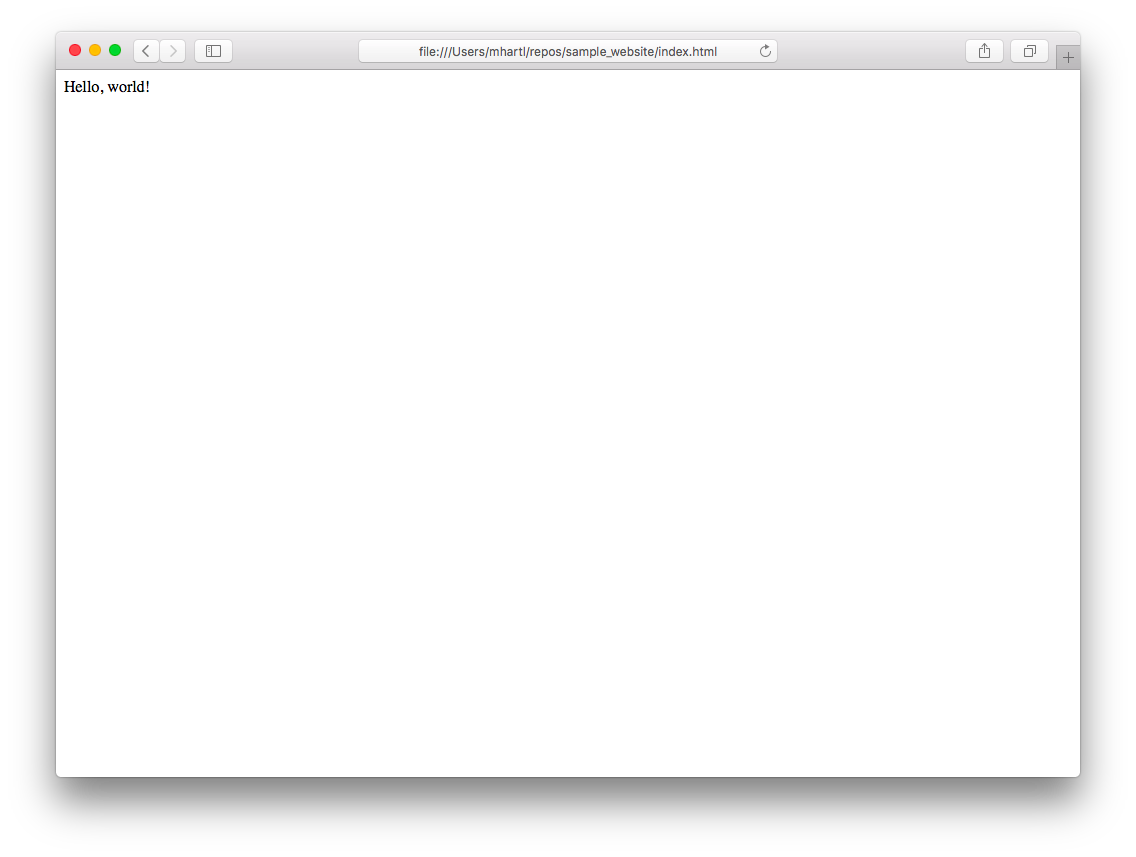
図 1.17のURLは、インターネット上ではなく自分の手元にある「ローカル」ファイルを指していることにご注意ください。
file:///Users/mhartl/repos/sample_website/index.html
このindexページはローカルシステム上にあり、実際のWebサイトにはまだデプロイされていません。
以下のように変更をローカルのGitリポジトリにコミットし、GitHub Pagesにpushすればデプロイされます。
$ git commit -am "Add a short paragraph"
$ git push
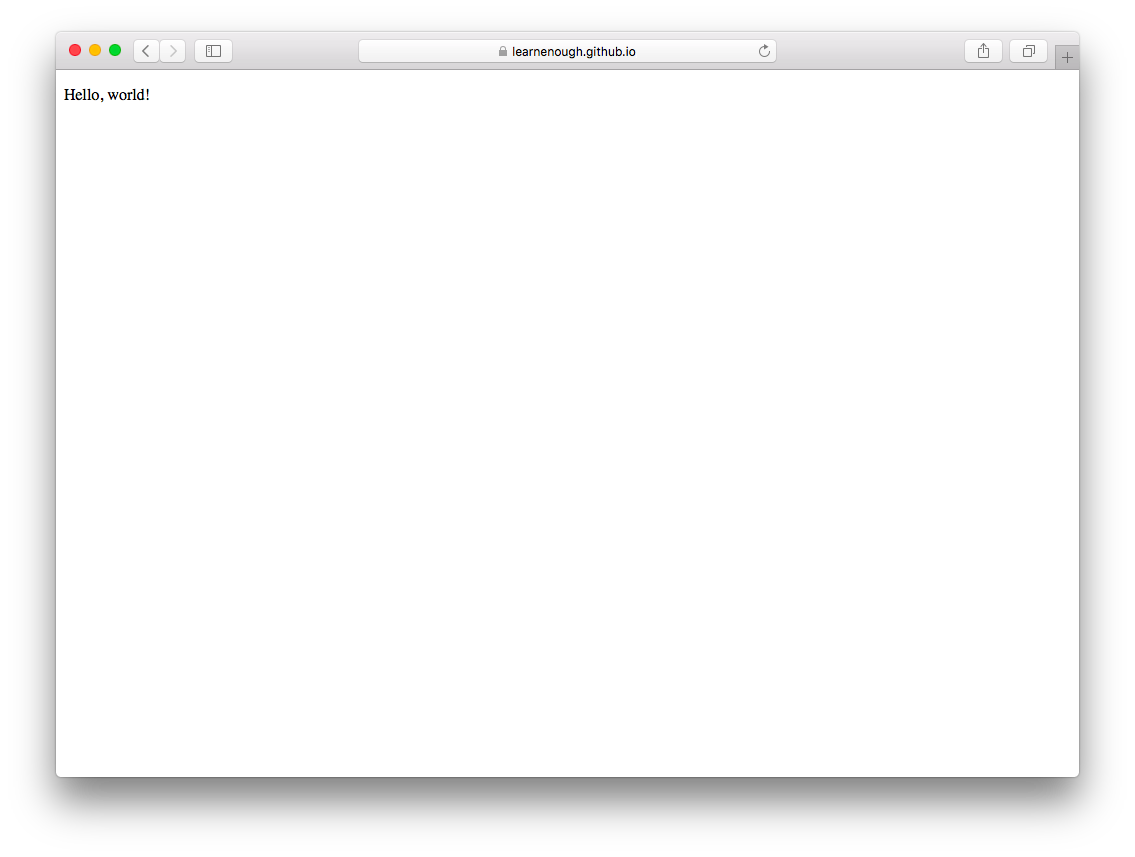
先ほどのサンプルWebサイトのGitHub Pages URL(リスト 1.3)を表示しているページをブラウザ上で更新すると、図 1.18のようになるはずです。デプロイ直後はGitHubPagesがサイトをロードするまでしばらく待つこともありますが、以後は爆速でレスポンスを返します。
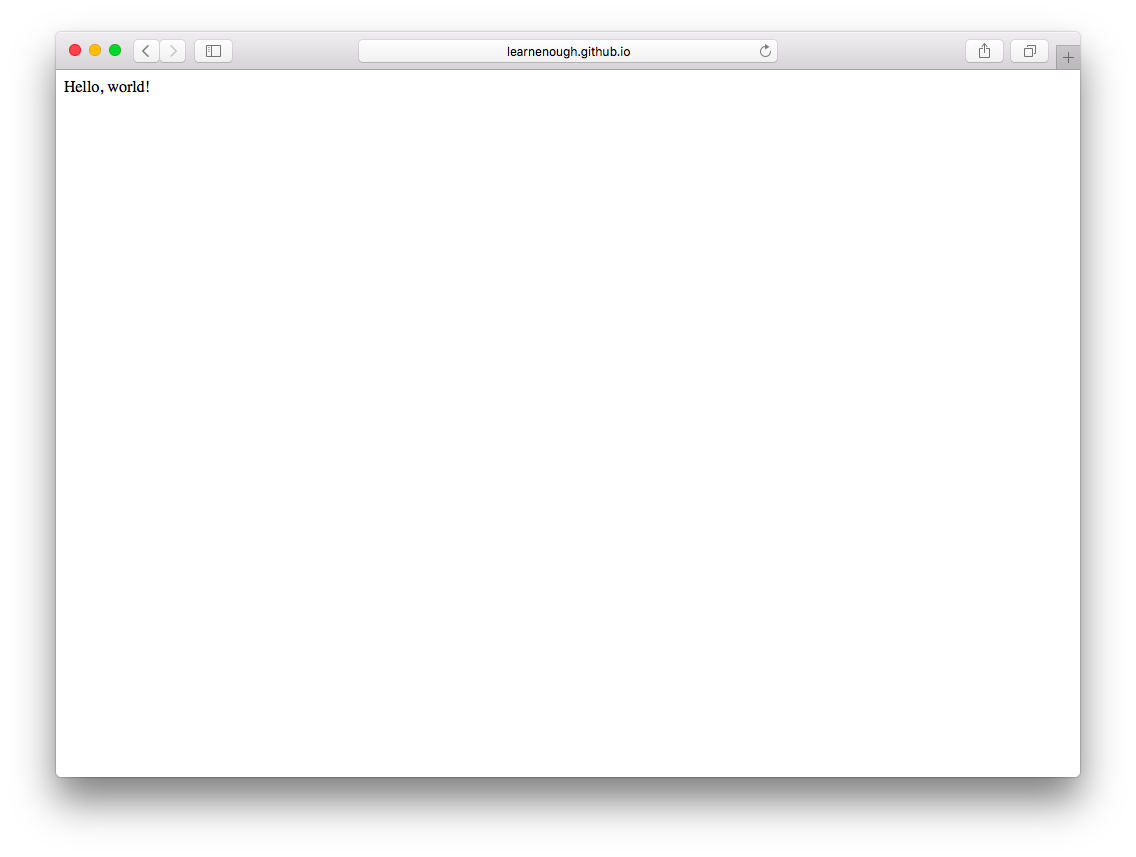
実際のWebサイトの表示はローカルの表示(図 1.17)と完全に同じですが、ブラウザのアドレスバーをよく見ると、URLがgithub.ioになっていることがわかります。つまり実際に動いている本物のWebなのです。
おめでとうございます!production(本番)Webサイトの公開に成功しました。
1.5 HTMLの基本的なスケルトン
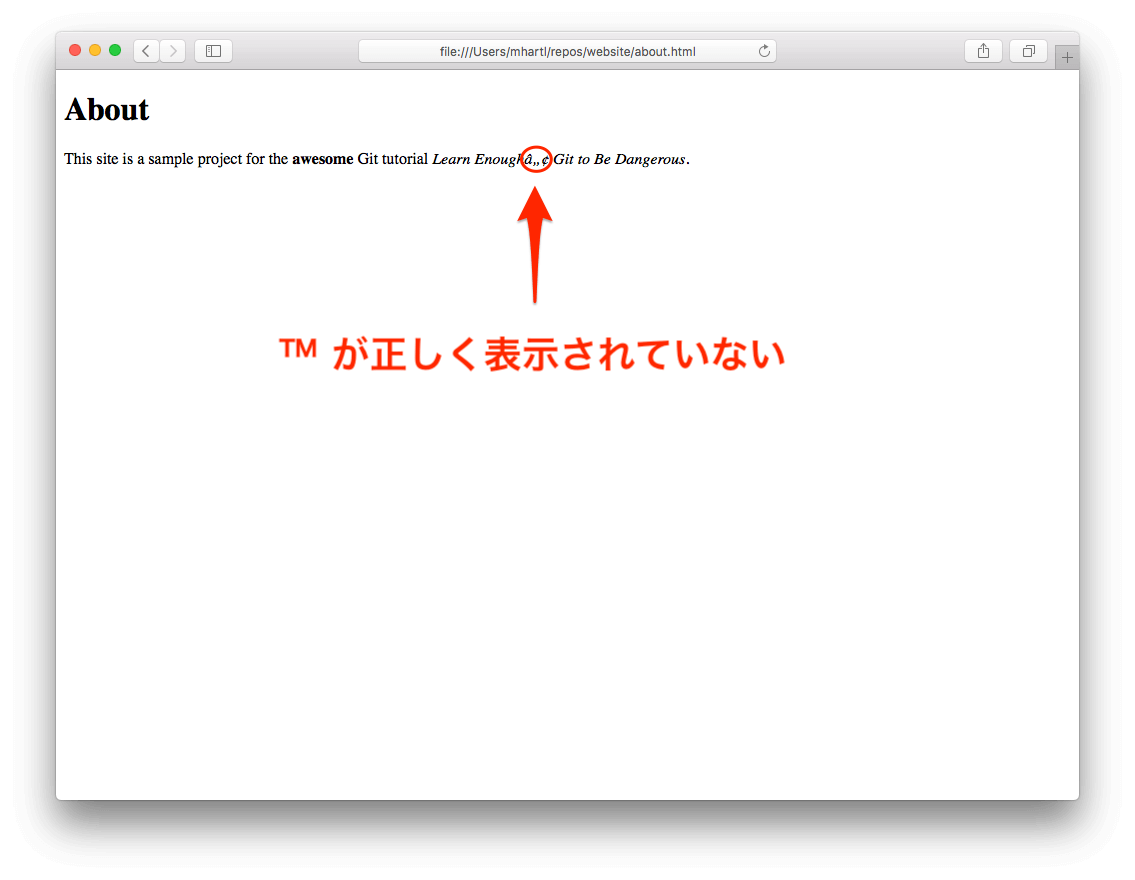
現代のWebブラウザは高度なフォールトトレランス機能27を備えているので、リスト 1.4のように素朴でいい加減なコードもレンダリングできますが、それに頼るのは危険です。『Git/GitHub編』でも解説したように、あるタグを追加しておかないと、トレードマーク記号「™ 」がブラウザ上で正しくレンダリングされなくなってしまいます。HTMLページが完全に検証(バリデーション)されていないと、まさにこうした問題が起きます。このような問題を避けるため、ここからは常に検証済みHTMLをサンプルWebページで使うことにします。検証済みHTMLを使うことで、ブラウザの種類が異なっていてもページが正しく表示されるようになります。
典型的なHTML構造(スケルトン)は、htmlタグを1つ持ち、その中に2つの要素(head要素を1つとbody要素を1つ)を持ちます。後者の2つの要素のタグは、以下のようにhtmlタグの中でネスト(nest: 入れ子)しています。
<html><head></head><body></body></html>
このままでは読みづらいので、スペースと改行を追加して、HTMLの構造がひと目で分かるようにするのが通例です。
<html>
<head>
</head>
<body>
</body>
</html>
HTMLではスペース文字を余分に追加しても無視されるので、このように整形してもブラウザ上の表示は変わりません。そしてこの方がドキュメントのソースコードを理解しやすくなります(コラム 1.4)。
HTMLを読みやすくするため、スペースや改行を適切に追加してドキュメントの構造を明確にし、ひと目でわかるようにする慣習が広く普及しています。最初のうちはやや違和感があるかもしれませんが、Web開発の世界ではソースコードが読みにくくならないようにするため(そしてHTMLコーダーを激怒させないため)、このスタイルを維持する習慣が定着しています。
一般に、HTMLをブラウザで表示すると余分なスペース(スペース文字の2つ以上の連続)は消えます。
<p>Hello, world!</p>
上のきれいなHTMLと、改行やスペースがだらしなく追加された下の残念なHTMLは、ブラウザ上でまったく同じに表示されます。
<p>Hello,
world!
</p>
HTMLを常日頃からこのように整形し、このスタイルを崩さないよう努めるのはよい習慣です。前者は、明らかに後者より読みやすくなっています。
ただしマークアップに手を加えていくうちに読みやすさが落ちることもあります。特にページが複雑になってテキストの文章量が増加したり、タグのネストが追加されると読みづらさが増します。コンテンツをシンプルに保ち、タグを見落とさないようにするためには、さらに厳密なスタイルで整形する必要があるでしょう。
どんな場合にも使えるユニバーサルなマークアップの整形方法というものは残念ながら存在しませんが、改行については少なくとも以下のことを守りましょう。
「タグに挟まれたコンテンツが短ければ、改行せず1行に収めること」
「ひとまとまりの長いテキストの中に含まれる要素(インライン要素)には改行やインデントを追加しないこと」
多くの開発者は、ひとまとまりの長いテキストの中に含まれる要素(インライン要素)には改行やインデントを追加しません(リスト 1.1の<strong>make them strong</strong>など)。なお、インライン要素の詳細や、いわゆるブロック要素との違いについては3.2で詳しく解説します。
また、英語やドイツ語や韓国語などの単語をスペースで区切る言語では「コンテンツが長くなったら改行を追加してインデントを追加する」手法もありますが、日本語コンテンツでは問題が生じるので、改行しないことをおすすめします28。
インデントのレベル(深さ)は開発者ごとに好みが分かれていますが、本チュートリアルでは「スペース2個」でインデントするスタイルを用いています。「スペース4個」もよく使われますが、私たちの経験上ではエディタの右側にすぐ達してしまいます。
スペースではなくTab文字でインデントするのを好む開発者もいますが、Tab文字によるスタイルは退けた方が無難でしょう。Tab文字の最大の問題はデバイスやエディタによって文字幅が異なってしまうことで、あるエディタではマークアップが気持ちよく整形されているのに、コマンドラインで見ると逃げ出したくなる可能性もあります。
そのようなときは、自分のエディタを設定してスペースを正しく使うようにすることが重要です29。詳しい方法については『テキストエディタ編』を読み返すか、「技術の成熟」精神を発揮して頑張りましょう(コラム 1.1)。
最後に、現代のテキストエディタの多くはHTMLを自動整形する機能を最初から内蔵していることは知っておく価値があります(VSCodeエディタの場合は「⇧⌥F」)。この機能は、巨大なHTMLファイルをインデントで整形するとき、特に外部の会社や顧客から渡されたファイルや、HTMLファイルがまともに整形されていない場合に大変重宝します。
こうした自動整形機能は一般に「オートコレクト」などと呼ばれます。特にプログラミング言語では、言語の構文を解析してより高度なコード整形を行う「lint」と呼ばれるツールも広く使われ始めています。こうした自動整形ツールは、大勢の作業者が共同作業するうえで書式のばらつきを防ぐ必須ツールとなっています。
共同作業では、作業者全員が自動整形の設定を完全に同じにしておくことが重要です(人によって違う書式に自動整形されていたらケンカの元になります)。しかし自動整形ツールを作業者の手元で使っていると、全員の設定を常に揃え続けるのに手間がかかります。エディタ内蔵の自動整形機能はエディタごとにまったく異なりますが、エディタは開発者ごとにはっきり好みが分かれるものなので、作業者全員のエディタを強制的に統一するのも簡単ではありません(おそらく反発を買うだけでしょう)。
そこで最近では、エディタ内蔵の自動整形に代えてエディタから作業者共通の自動整形ツールを呼び出したり、GitHubなどのリポジトリ上にコードをpushすると自動的に何らかのlintツールが走るように設定することも広く行われています。ただしツールは流行り廃りが激しいので、一度慣れたツールをずっと使い続けられる可能性は少ないでしょう。
いずれにしろ、今後は何らかのツールによる自動整形が当たり前になり、コードを自分勝手な書式で書くことはなくなるでしょう。
HTMLの中で<head>と</head>で囲まれているセクションは、「メタデータ(metadata)」を定義するヘッダーコンテナです。なおメタデータとは「データに関するデータ」のことです。
この<head>セクションはブラウザ上では表示されませんが、ブラウザに対してさまざまな指定を行えます。たとえば、コンテンツを正しく表示するのに必要なCSSファイルやJavaScriptファイルの置き場所などの情報を、ブラウザ上に表示せずに指定できます。なお、HTMLヘッダーに追加できる項目について詳しくは『CSS & Design編』で学びます。
<body>と</body>に囲まれたコンテンツは、ブラウザに表示されます。どんなWebサイトでも、コンテンツは必ずHTMLのbodyタグの内側に置かれています。
このHTMLスケルトンを完成させるには、あと2つの要素が必要です(リスト 1.5)。最初に、ブラウザに「document type」を知らせる要素が必要です。これは省略できません。次に、head要素の内側に、空ではないtitle要素を定義する必要もあります。これは一応省略可能ではありますが、省略しないことが強く推奨されています。
<!DOCTYPE html>
<html>
<head>
<title>ページタイトル</title>
</head>
<body>
</body>
</html>
上のDOCTYPEだけは他のタグと書式がかなり異なっていますが、これは「そういうものだ」と考えましょう。これが一体何なのかは気にする必要はありません30。もうひとつのtitleタグは、図 1.6で見たstrongタグや、1.4で見たpタグと同様、開始タグと終了タグがあります。
W3CのHTML validatorというサイトでリスト 1.5のHTMLを検証(バリデーション)してみると、HTML5であると判定されます(図 1.20)。
なお、titleの中身が空なのは違反ですが、bodyの中身は空でも問題ありません。
もうひとつ注目いただきたいのは、このページに関する「エラー」は何も表示されませんが、「lang属性(attribute)がない」という「警告(warning)」が1件表示されるという点です。この警告は後ほど3.3.1で修正する予定です。

『Git/GitHub編』の図 1.19でもうひとつ学んだのは、コンテンツをどの「文字セット(character)」で表示するかをブラウザに伝える必要があるということです。Unicodeを文字セットに指定すると、「™」「©」などの記号や「voilà」などのアクセント文字やさまざまな言語特有の文字(漢字やひらがなも含む)などの膨大な文字セットが使えます。これを行うには、リスト 1.6のようにheadにmetaタグを追加します。
metaタグを追加する
<!DOCTYPE html>
<html>
<head>
<title>ページタイトル</title>
<meta charset="utf-8">
</head>
<body>
</body>
</html>
現代のWebサイトはほぼ間違いなく文字セットをUnicodeにしていますので、新規案件でUnicode以外の文字セットを使うことはまずないでしょう(コラム 1.5)。
Unicode普及前の日本では「Shift_JIS」や「EUC-JP」「ISO-2022-JP(俗にJISコード)」といったさまざまなエンコード方式が乱立していました。これらは多言語を混在させることもできず、いわゆる文字化けもしばしば発生しました。Unicodeが普及した現在は、文字化けを見かけることもほぼなくなりました。
文字セットの世界ではUnicodeが勝利しましたが、Unicodeの規格の中には実は「UTF-8」「UTF-16」という複数のエンコード方式(encoding)が存在します(他にマイナーな「UTF-32」なども一応ありますが)。UTF-8は設計の優れたエンコード方式で、特にプログラミングの世界ではほぼ勝利を収めています。UTF-16はWindowsの内部エンコード方式に採用されてしまったために、Windowsユーザーから受け取る生テキストファイルはUTF-16でエンコードされていることがほとんどです。テキストエディタはUTF-8やUTF-16を自動的に認識して対応するので、通常はほぼ気にしなくても大丈夫です(これまでのチュートリアルはすべてUTF-8ベースになっています)。ただしプログラミングではUTF-8とUTF-16の違いに注意が必要になることもあります。
なおmetaタグは「空要素(empty element)」と呼ばれる特殊なタグなので、閉じタグが存在しません。そのため、空要素は「自己終了タグ(self-closing tag)」とも呼ばれます。
以上でHTMLのスケルトンが完成しました(図 1.21)31。リスト 1.7を参考のために再掲載します。

1 <!DOCTYPE html>
2 <html>
3 <head>
4 <title>ページタイトル</title>
5 <meta charset="utf-8">
6 </head>
7 <body>
8 </body>
9 </html>
HTMLスケルトンは大事なので、要素を1行ずつおさらいしておきましょう。
- doctype宣言
-
html開始タグ -
head開始タグ -
titleタグ(開始タグと終了タグでページタイトルを挟む) - 文字セットを定義する
metaタグ -
head終了タグ -
body開始タグ -
body終了タグ -
html終了タグ
先ほどのリスト 1.4のパラグラフを、リスト 1.7のスケルトンに当てはめれば、サンプルWebサイトで使う最初の正しいHTMLページができあがります(リスト 1.8)。
index.html
<!DOCTYPE html>
<html>
<head>
<title>ページタイトル</title>
<meta charset="utf-8">
</head>
<body>
<p>Hello, world!</p>
</body>
</html>
リスト 1.4から引用したパラグラフは、HTML標準の必須条件に基づいてリスト 1.8ではbodyタグの内側に置かれていることにご注意ください。
ブラウザ画面を更新すると、リスト 1.8の結果は実質的に図 1.18のときと同じになります。ページ本文における唯一の違いは、図 1.22のようにパラグラフの周りの余白がわずかに増えていることです。
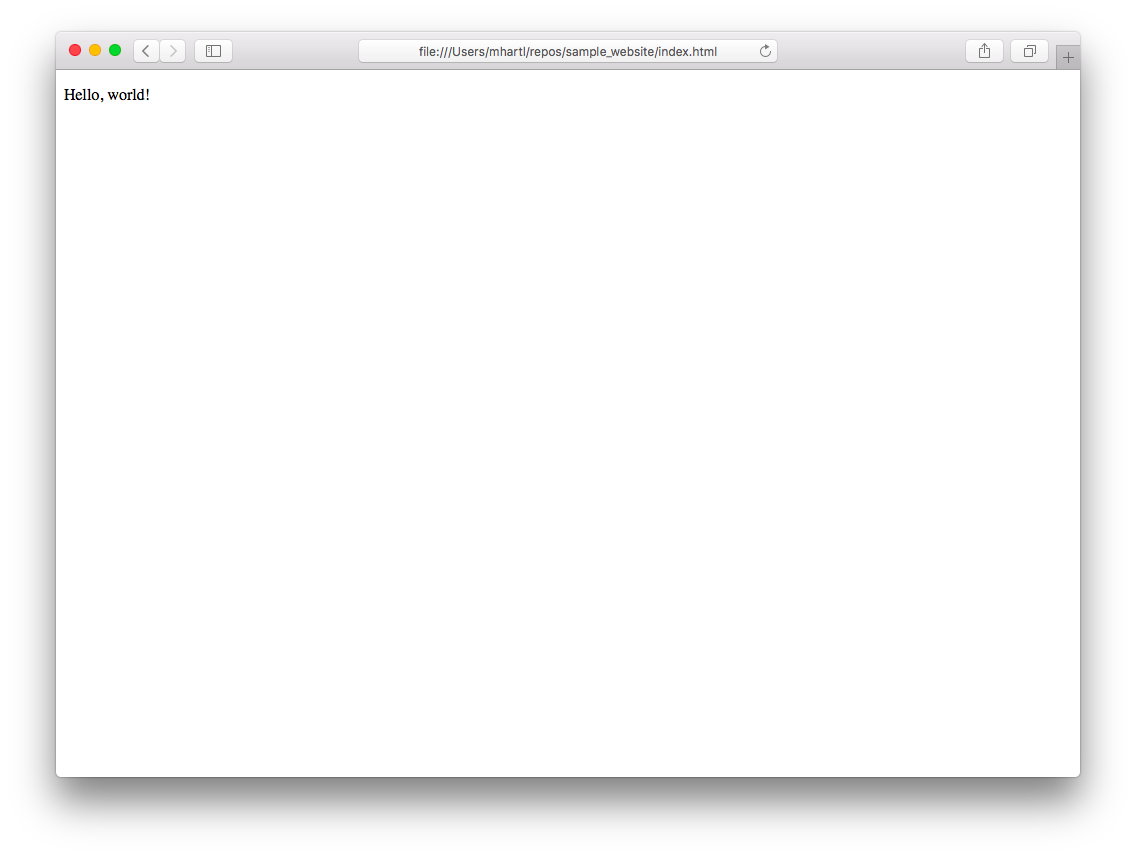
ところで、ページタイトルの表示方法はブラウザごとに多少違いがあります。図 1.23のようにデフォルトのタブにタイトルを表示するブラウザもあれば、図 1.24のように2つ目のタブを追加するまでタイトルをタブに表示しないブラウザもあります。このページタイトルはブラウザによっては表示されないことがありますが、それでもHTML標準において必須とされているので、省略すべきではありません。
またページタイトルは、文章読み上げ機能(screen reader)や、検索エンジンのクローラー32にとっても重要な情報源でもあるので、その意味でも省略すべきではありません。
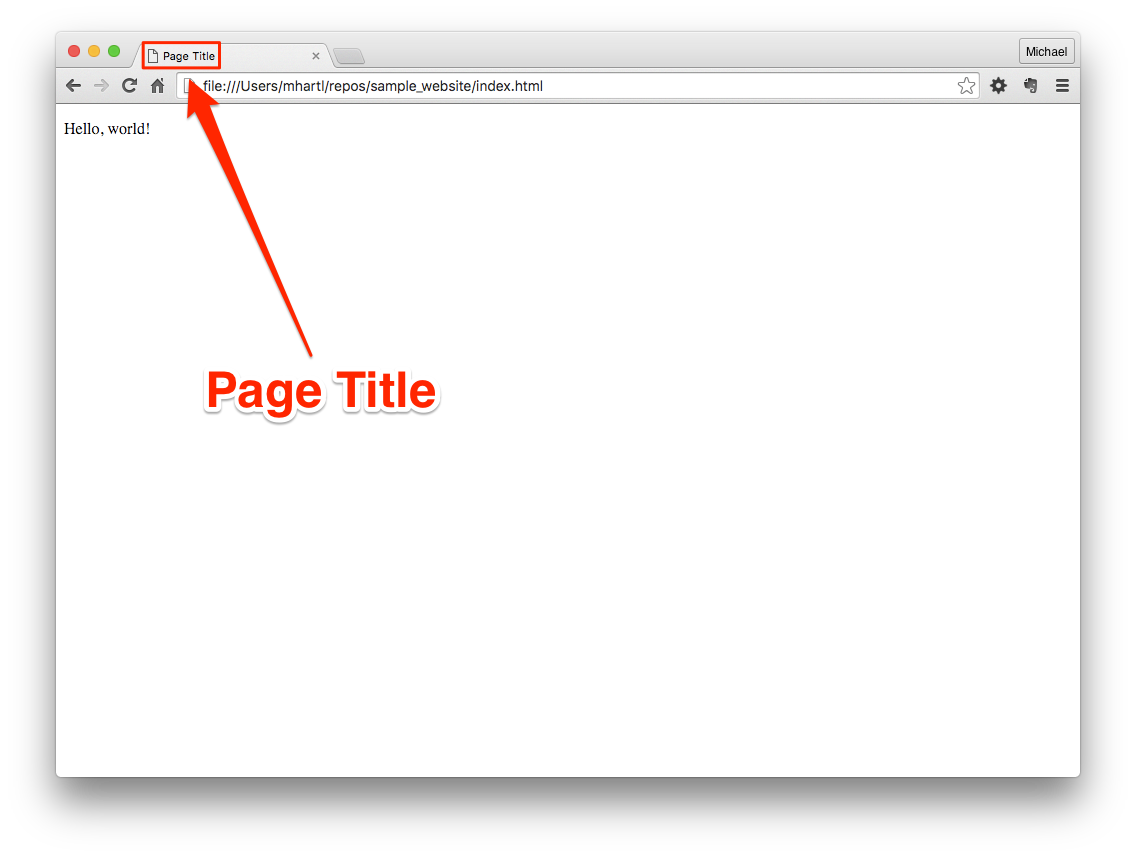
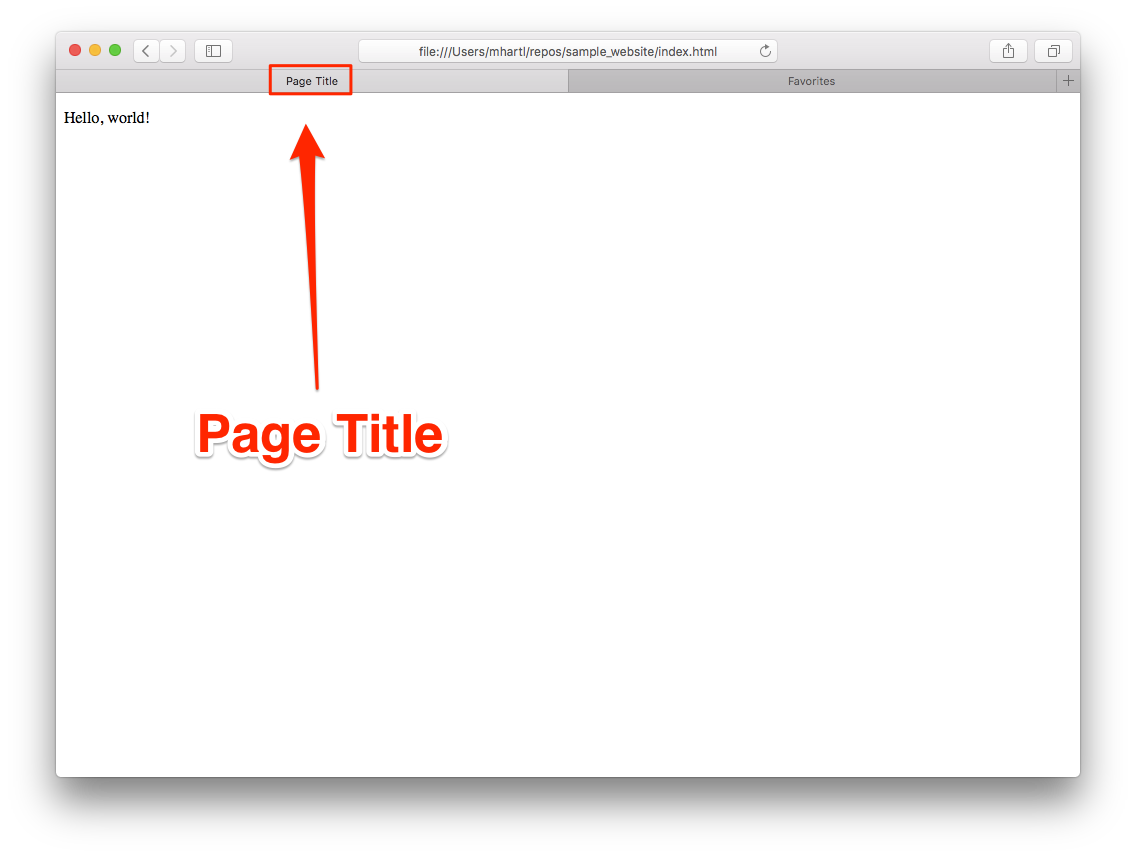
以上で、変更内容をコミットしてGitHub Pagesに結果をpushする準備が整いました。
$ git commit -am "Convert index page to fully valid HTML"
$ git push
結果は図 1.25のようになります。
1.5.1 演習問題
- リスト 1.6のHTMLが正しいことをHTML validatorで確認してください。
-
index.htmlの</title>タグをリスト 1.9のとおりに削除すると、図 1.26のように表示がおかしくなる(タイトルが消える)ことを確認してください。これは閉じタグの重要性を示しています。これをHTML validatorでチェックするとバリデーションが失敗する(エラーが表示される)ことを確認してください。 -
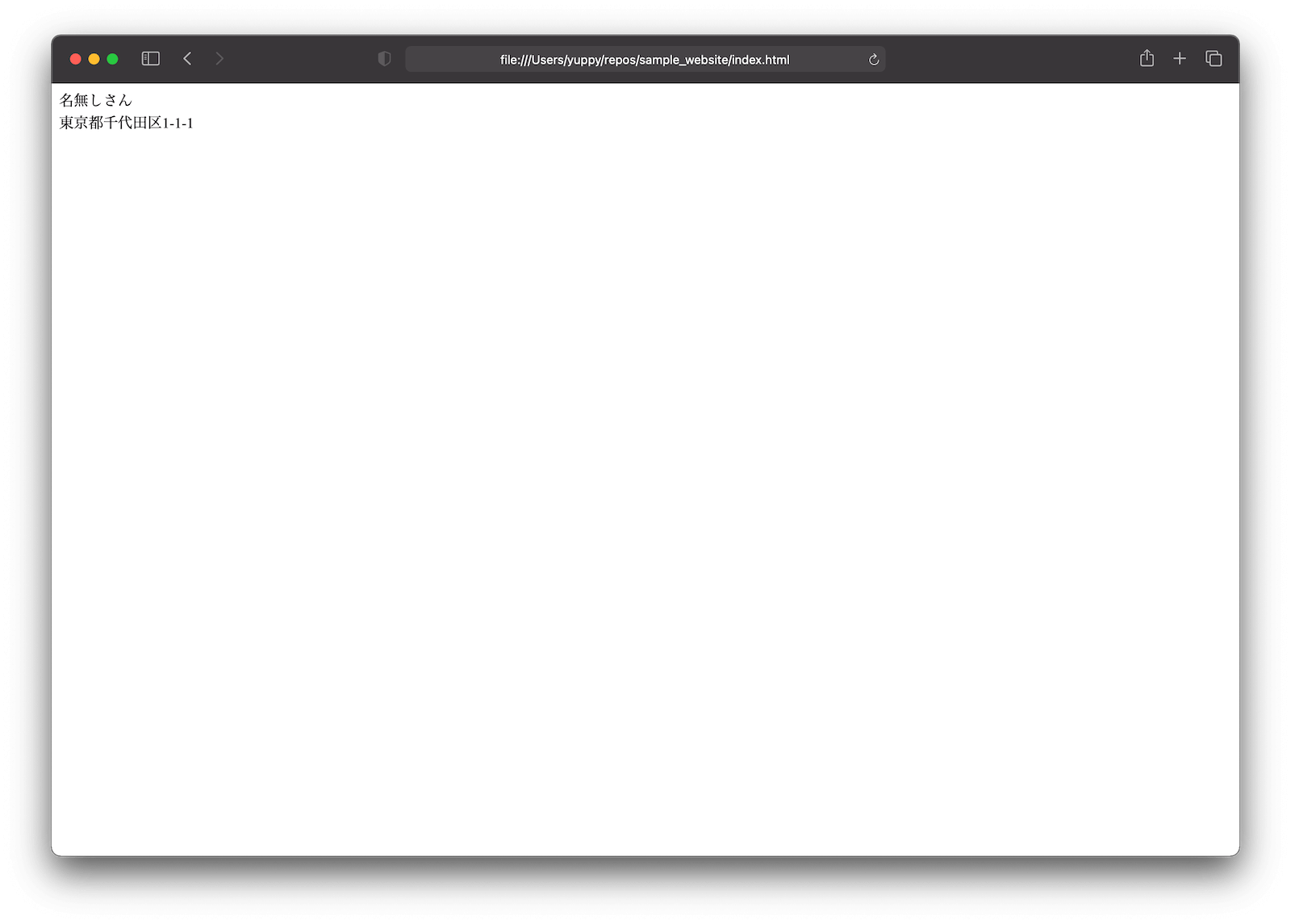
index.htmlの中身をリスト 1.10で置き換え、住所に含まれるホワイトスペース(スペースや改行文字などを合わせた呼び方)がブラウザで表示されない(無視される)ことを確認してください。 - 住所の各行末尾の改行位置に
<br>タグ(break: 改行)タグを追加して、ブラウザ上の住所も改行されるようにしてください(図 1.27)
index.html
<!DOCTYPE html>
<html>
<head>
<title>ページタイトル
<meta charset="utf-8">
</head>
<body>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>私は誰?</title>
<meta charset="utf-8">
</head>
<body>
名無しさん
東京都千代田区1-1-1
</body>
</html>
strongタグの中身(つまり<strong>と</strong>で挟まれた文字列)が英文だった場合は、途中で改行されていたとしてもブラウザは改行を「無視」します。つまりブラウザは、改行がなかったかのように、英語の文字列をひと続きのテキストとして表示します。chsh -s /bin/bashを実行し、パスワードを入力してから「ターミナル」アプリを終了し、再度起動すれば完了です。途中でいろいろなメッセージが表示されますが、無視しても大丈夫です。詳しくはLearn Enoughブログの記事「Using Z Shell on Macs with the Learn Enough Tutorials(英語)」をご覧くださいmkdir -pというコマンドについては、『Git/GitHub編』の「1.2 リポジトリを初期化する」でも解説しています。特に断りのない限り、『HTML編』で扱われているコマンドは、すべて既刊の3つのチュートリアルのいずれかで解説されています。本チュートリアルで、よくわからないコマンドを見かけたら、既刊のチュートリアルの中を探すことをおすすめします。index.htmlにすべき理由については、この後すぐに説明します。touchコマンドで作成したのは単に私の好みによるものです。なお、これで作成したファイルの中身は空になります。ファイルを作成するついでに何かテキストも入れておきたいのであれば、echo hello > index.htmlを実行する手もあります。.html拡張子を認識しています。DOCTYPEの前に感嘆符がある理由もわかりません。
Railsチュートリアルは YassLab 社によって運営されています。
コンテンツを継続的に提供するため、書籍・動画・質問対応サービスなどもご検討していただけると嬉しいです。
研修支援や教材連携にも対応しています。note マガジンや YouTube チャンネルも始めたので、よければぜひ遊びに来てください!